
Фреймворк для оценки LLM
Документация | Метрики и возможности | Быстрый старт | Интеграции | Платформа DeepEval

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval — это простой в использовании фреймворк с открытым исходным кодом для оценки и тестирования систем на основе больших языковых моделей (LLM). Он аналогичен Pytest, но специализирован для модульного тестирования выходных данных LLM. DeepEval использует последние исследования для оценки выходных данных LLM на основе таких метрик, как G-Eval, галлюцинации, релевантность ответа, RAGAS и других, с применением LLM и различных NLP-моделей, работающих локально на вашем компьютере.
Независимо от того, являются ли ваши LLM-приложения RAG-конвейерами, чат-ботами, AI-агентами, реализованными через LangChain или LlamaIndex, DeepEval предоставляет все необходимое. С его помощью вы можете легко определить оптимальные модели, промты и архитектуру для улучшения вашего RAG-конвейера, агентных рабочих процессов, предотвращения дрейфа промтов или даже перехода с OpenAI на хостинг собственной модели Deepseek R1 с уверенностью.
[!IMPORTANT] Нужно место для хранения тестовых данных DeepEval 🏡❤️? Зарегистрируйтесь на платформе DeepEval, чтобы сравнивать итерации вашего LLM-приложения, генерировать и делиться отчетами о тестировании и многое другое.
Хотите обсудить оценку LLM, нужна помощь в выборе метрик или просто поздороваться? Присоединяйтесь к нашему Discord.
🔥 Метрики и возможности
🥳 Теперь вы можете делиться результатами тестов DeepEval в облаке напрямую на инфраструктуре Confident AI
- Поддержка как сквозной, так и компонентной оценки LLM.
- Большой выбор готовых метрик для оценки LLM (все с пояснениями), работающих на ЛЮБОЙ LLM по вашему выбору, статистических методах или NLP-моделях, выполняющихся локально на вашем компьютере:
- G-Eval
- DAG (глубокий ациклический граф)
- Метрики RAG:
- Релевантность ответа
- Достоверность
- Контекстуальное воспроизведение
- Контекстуальная точность
- Контекстуальная релевантность
- RAGAS
- Метрики агентов:
- Завершенность задачи
- Корректность инструментов
- Другие:
- Галлюцинации
- Суммаризация
- Смещение
- Токсичность
- Метрики диалогов:
- Сохранение знаний
- Полнота диалога
- Релевантность диалога
- Соблюдение роли
- и др.
- Создавайте собственные метрики, автоматически интегрируемые в экосистему DeepEval.
- Генерация синтетических наборов данных для оценки.
- Легкая интеграция с ЛЮБОЙ средой CI/CD.
- Тестирование безопасности вашего LLM-приложения на 40+ уязвимостей в несколько строк кода, включая:
- Токсичность
- Смещение
- SQL-инъекции
- и др., с использованием 10+ стратегий усиления атак, таких как инъекции промтов.
- Легко сравнивайте ЛЮБУЮ LLM на популярных бенчмарках в менее чем 10 строках кода, включая:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% интеграция с Confident AI для полного цикла оценки:
- Создание/аннотирование наборов данных для оценки в облаке
- Бенчмаркинг LLM-приложения с использованием набора данных и сравнение с предыдущими итерациями для экспериментов с оптимальными моделями/промтами
- Настройка метрик для пользовательских результатов
- Отладка результатов оценки через трассировку LLM
- Мониторинг и оценка ответов LLM в продукте для улучшения наборов данных реальными данными
- Повторение до совершенства
[!NOTE] Confident AI — это платформа DeepEval. Создайте аккаунт здесь.
🔌 Интеграции
- 🦄 LlamaIndex, для модульного тестирования RAG-приложений в CI/CD
- 🤗 Hugging Face, для включения оценки в реальном времени во время тонкой настройки LLM
🚀 Быстрый старт
Предположим, ваше LLM-приложение — это RAG-чатбот для поддержки клиентов; вот как DeepEval может помочь протестировать его.
Установка
pip install -U deepeval
Создание аккаунта (рекомендуется)
Использование платформы deepeval позволит вам генерировать отчеты о тестировании в облаке. Это бесплатно, не требует дополнительного кода, и мы настоятельно рекомендуем попробовать.
Для входа выполните:
deepeval login
Следуйте инструкциям в CLI, чтобы создать аккаунт, скопировать API-ключ и вставить его в CLI. Все тестовые случаи будут автоматически записываться (подробнее о конфиденциальности данных здесь).
Написание первого тестового случая
Создайте тестовый файл:
touch test_chatbot.py
Откройте test_chatbot.py и напишите первый тестовый случай для сквозной оценки с помощью DeepEval, который рассматривает ваше LLM-приложение как черный ящик:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
Установите OPENAI_API_KEY как переменную окружения (вы также можете использовать собственную модель, подробнее см. документацию):
export OPENAI_API_KEY="..."
И наконец, запустите test_chatbot.py в CLI:
deepeval test run test_chatbot.py
Поздравляем! Ваш тест должен был пройти ✅ Давайте разберем, что произошло.
- Переменная
inputимитирует пользовательский ввод, аactual_output— это предполагаемый вывод вашего приложения. - Переменная
expected_outputпредставляет идеальный ответ для данногоinput, аGEval— это исследовательская метрика отdeepevalдля оценки выходных данных LLM с человеческой точностью. - В этом примере критерий
criteria— это корректностьactual_outputотносительноexpected_output. - Все оценки метрик варьируются от 0 до 1, а порог
threshold=0.5определяет, прошел ли тест.
Читайте нашу документацию для получения дополнительной информации о других вариантах сквозной оценки, использовании дополнительных метрик, создании собственных метрик и интеграции с такими инструментами, как LangChain и LlamaIndex.
Оценка вложенных компонентов
Если вы хотите оценить отдельные компоненты вашего LLM-приложения, вам нужно выполнить компонентную оценку — мощный способ оценки любого компонента в системе LLM.
Просто трассируйте "компоненты", такие как вызовы LLM, ретриверы, вызовы инструментов и агенты, с помощью декоратора @observe, чтобы применять метрики на уровне компонентов. Трассировка с deepeval ненавязчива (подробнее здесь) и помогает избежать переписывания кода только для оценки:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
Вы можете узнать все о компонентной оценке здесь.
Оценка без интеграции с Pytest
Альтернативно, вы можете выполнять оценку без Pytest, что больше подходит для среды ноутбуков.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
Использование автономных метрик
DeepEval чрезвычайно модулен, что позволяет легко использовать любые из наших метрик. Продолжая предыдущий пример:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
Обратите внимание, что некоторые метрики предназначены для RAG-конвейеров, а другие — для тонкой настройки. Убедитесь, что выбрали подходящие для вашего случая использования.
Оценка набора данных / тестовых случаев массово
В DeepEval набор данных — это просто коллекция тестовых случаев. Вот как можно оценить их массово:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
Альтернативно, хотя мы рекомендуем использовать deepeval test run, вы можете оценить набор данных/тестовые случаи без интеграции с Pytest:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Оценка LLM с Confident AI
Полный цикл оценки LLM возможен только с платформой DeepEval. Она позволяет:
- Создавать/аннотировать наборы данных для оценки в облаке
- Сравнивать LLM-приложение с предыдущими итерациями для экспериментов с оптимальными моделями/промтами
- Настраивать метрики для пользовательских результатов
- Отлаживать результаты оценки через трассировку LLM
- Мониторить и оценивать ответы LLM в продукте для улучшения наборов данных реальными данными
- Повторять до совершенства
Всё о Confident AI, включая его использование, доступно здесь.
Для начала войдите через CLI:
deepeval login
Следуйте инструкциям для входа, создания аккаунта и вставки API-ключа в CLI.
Теперь снова запустите тестовый файл:
deepeval test run test_chatbot.py
После завершения теста в CLI появится ссылка. Вставьте её в браузер, чтобы просмотреть результаты!
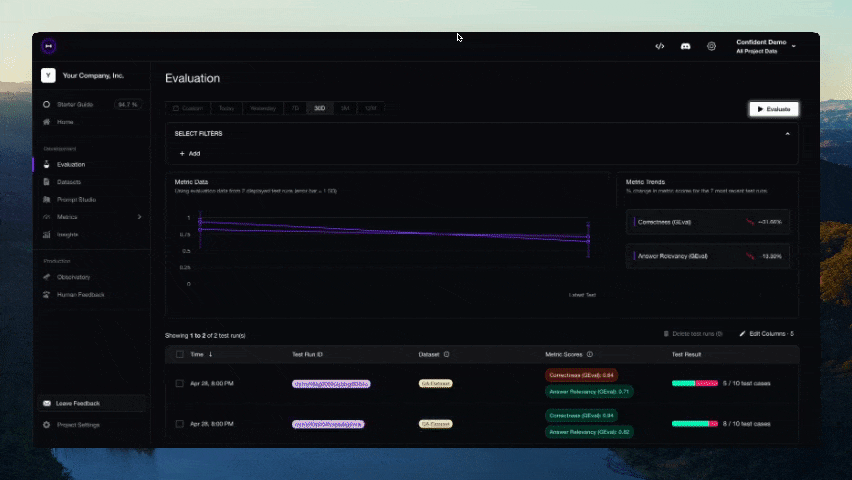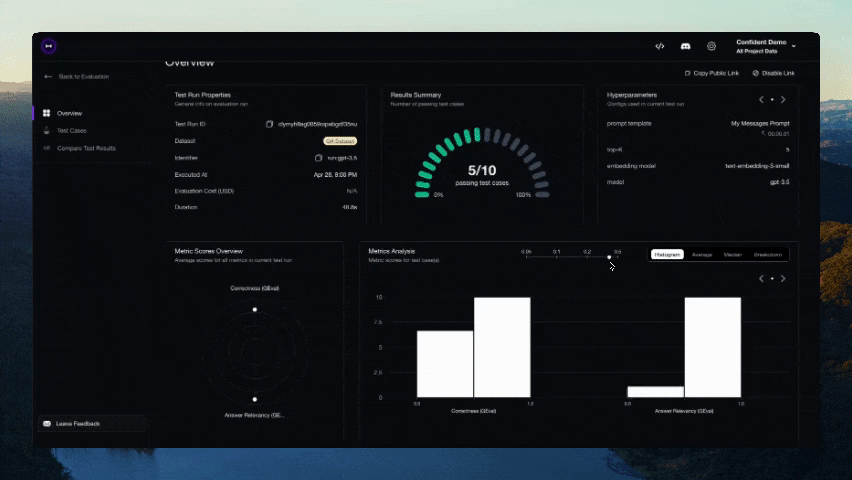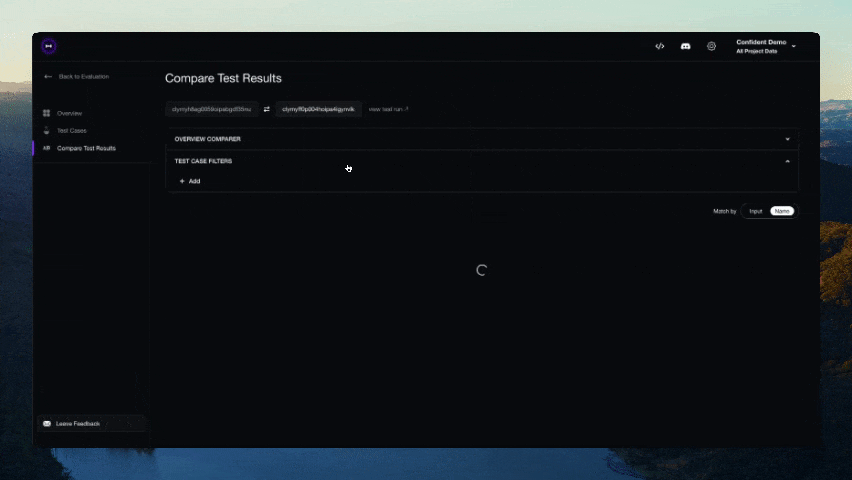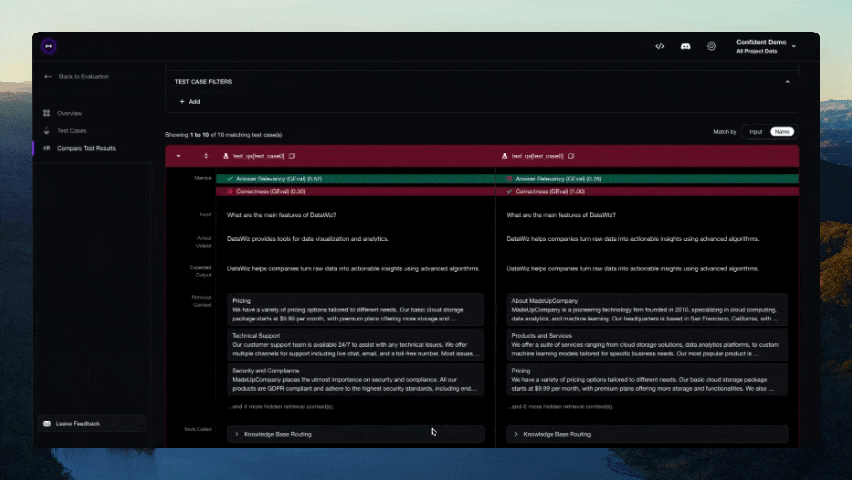
Участие
Пожалуйста, прочитайте CONTRIBUTING.md для получения информации о нашем кодексе поведения и процессе отправки pull request'ов.
Дорожная карта
Функции:
- Интеграция с Confident AI
- Реализация G-Eval
- Реализация метрик RAG
- Реализация метрик диалогов
- Создание наборов данных для оценки
- Тестирование безопасности
- Пользовательские метрики DAG
- Защитные механизмы
Авторы
Разработано основателями Confident AI. По всем вопросам обращайтесь на [email protected].
Лицензия
DeepEval лицензирован под Apache 2.0 — подробности см. в файле LICENSE.md.