
Das LLM-Evaluierungsframework
Dokumentation | Metriken und Funktionen | Erste Schritte | Integrationen | DeepEval-Plattform

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval ist ein einfach zu verwendendes, Open-Source-Framework zur Evaluierung und Testung von Large-Language-Model-Systemen. Es ähnelt Pytest, ist jedoch speziell für Unit-Tests von LLM-Ausgaben konzipiert. DeepEval integriert die neuesten Forschungsergebnisse, um LLM-Ausgaben anhand von Metriken wie G-Eval, Halluzination, Antwortrelevanz, RAGAS usw. zu bewerten, wobei LLMs und verschiedene andere NLP-Modelle verwendet werden, die lokal auf Ihrem Rechner laufen.
Egal, ob Ihre LLM-Anwendungen RAG-Pipelines, Chatbots oder KI-Agenten sind, die über LangChain oder LlamaIndex implementiert sind – DeepEval hat Sie abgedeckt. Damit können Sie leicht die optimalen Modelle, Prompts und Architekturen ermitteln, um Ihre RAG-Pipeline zu verbessern, agentenbasierte Workflows zu optimieren, Prompt-Drifting zu verhindern oder sogar selbstbewusst von OpenAI auf Ihr eigenes Deepseek R1 umzusteigen.
[!IMPORTANT] Brauchen Sie einen Ort, an dem Ihre DeepEval-Testdaten leben können �❤️? Melden Sie sich bei der DeepEval-Plattform an, um Iterationen Ihrer LLM-App zu vergleichen, Testberichte zu generieren und zu teilen und vieles mehr.
Möchten Sie über LLM-Evaluierung sprechen, Hilfe bei der Auswahl von Metriken benötigen oder einfach Hallo sagen? Kommen Sie in unseren Discord.
🔥 Metriken und Funktionen
🥳 Sie können DeepEvals Testergebnisse jetzt direkt in der Cloud auf der Infrastruktur von Confident AI teilen.
- Unterstützung sowohl für End-to-End- als auch für komponentenbasierte LLM-Evaluierung.
- Große Auswahl an sofort einsatzbereiten LLM-Evaluierungsmetriken (alle mit Erklärungen), betrieben von JEDEM LLM Ihrer Wahl, statistischen Methoden oder NLP-Modellen, die lokal auf Ihrem Rechner laufen:
- G-Eval
- DAG (Deep Acyclic Graph)
- RAG-Metriken:
- Antwortrelevanz
- Vertrauenswürdigkeit
- Kontextuelle Erinnerung
- Kontextuelle Präzision
- Kontextuelle Relevanz
- RAGAS
- Agentenmetriken:
- Aufgabenabschluss
- Werkzeugkorrektheit
- Andere:
- Halluzination
- Zusammenfassung
- Voreingenommenheit
- Toxizität
- Konversationsmetriken:
- Wissensspeicherung
- Konversationsvollständigkeit
- Konversationsrelevanz
- Rolleneinhaltung
- usw.
- Erstellen Sie Ihre eigenen benutzerdefinierten Metriken, die automatisch in das DeepEval-Ökosystem integriert werden.
- Generieren Sie synthetische Datensätze für die Evaluierung.
- Nahtlose Integration in JEDE CI/CD-Umgebung.
- Red-Teaming für Ihre LLM-Anwendung für 40+ Sicherheitslücken mit wenigen Codezeilen, einschließlich:
- Toxizität
- Voreingenommenheit
- SQL-Injection
- usw., unter Verwendung von 10+ fortschrittlichen Angriffsverstärkungsstrategien wie Prompt-Injections.
- Benchmarking von JEDEM LLM auf beliebten LLM-Benchmarks in weniger als 10 Codezeilen, darunter:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% integriert mit Confident AI für den vollständigen Evaluierungslebenszyklus:
- Kuratieren/Annotieren von Evaluierungsdatensätzen in der Cloud
- Benchmarking der LLM-App mit Datensätzen und Vergleich mit früheren Iterationen, um zu experimentieren, welche Modelle/Prompts am besten funktionieren
- Feinabstimmung von Metriken für benutzerdefinierte Ergebnisse
- Debugging von Evaluierungsergebnissen über LLM-Traces
- Überwachung & Evaluierung von LLM-Antworten im Produkt, um Datensätze mit realen Daten zu verbessern
- Wiederholen bis zur Perfektion
[!NOTE] Confident AI ist die DeepEval-Plattform. Erstellen Sie ein Konto hier.
🔌 Integrationen
- 🦄 LlamaIndex, um RAG-Anwendungen in CI/CD zu unit-testen
- 🤗 Hugging Face, um Echtzeit-Evaluierungen während des LLM-Fine-Tunings zu ermöglichen
🚀 Schnellstart
Angenommen, Ihre LLM-Anwendung ist ein RAG-basierter Kundensupport-Chatbot; hier erfahren Sie, wie DeepEval Ihnen helfen kann, das von Ihnen Erstellte zu testen.
Installation
pip install -U deepeval
Konto erstellen (dringend empfohlen)
Die Verwendung der deepeval-Plattform ermöglicht es Ihnen, teilbare Testberichte in der Cloud zu generieren. Sie ist kostenlos, erfordert keinen zusätzlichen Code und wir empfehlen dringend, sie auszuprobieren.
Um sich anzumelden, führen Sie aus:
deepeval login
Folgen Sie den Anweisungen in der CLI, um ein Konto zu erstellen, kopieren Sie Ihren API-Schlüssel und fügen Sie ihn in die CLI ein. Alle Testfälle werden automatisch protokolliert (weitere Informationen zum Datenschutz finden Sie hier).
Ihren ersten Testfall schreiben
Erstellen Sie eine Testdatei:
touch test_chatbot.py
Öffnen Sie test_chatbot.py und schreiben Sie Ihren ersten Testfall, um eine End-to-End-Evaluierung mit DeepEval durchzuführen, die Ihre LLM-App als Black-Box behandelt:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
Setzen Sie Ihre OPENAI_API_KEY als Umgebungsvariable (Sie können auch mit Ihrem eigenen benutzerdefinierten Modell evaluieren; weitere Details finden Sie in diesem Teil unserer Dokumentation):
export OPENAI_API_KEY="..."
Und führen Sie schließlich test_chatbot.py in der CLI aus:
deepeval test run test_chatbot.py
Glückwunsch! Ihr Testfall sollte bestanden worden sein ✅ Lassen Sie uns analysieren, was passiert ist.
- Die Variable
inputsimuliert eine Benutzereingabe, undactual_outputist ein Platzhalter für das, was Ihre Anwendung basierend auf dieser Eingabe ausgeben soll. - Die Variable
expected_outputstellt die ideale Antwort für eine gegebeneinputdar, undGEvalist eine forschungsgestützte Metrik vondeepeval, mit der Sie Ihre LLM-Ausgaben mit menschlicher Genauigkeit auf beliebige Kriterien bewerten können. - In diesem Beispiel ist das Metrik-
criteriadie Korrektheit deractual_outputbasierend auf der bereitgestelltenexpected_output. - Alle Metrikwerte reichen von 0 - 1, wobei der
threshold=0.5letztendlich bestimmt, ob Ihr Test bestanden wurde oder nicht.
Lesen Sie unsere Dokumentation für weitere Informationen zu weiteren Optionen für End-to-End-Evaluierungen, zur Verwendung zusätzlicher Metriken, zur Erstellung eigener benutzerdefinierter Metriken und Tutorials zur Integration mit anderen Tools wie LangChain und LlamaIndex.
Evaluierung verschachtelter Komponenten
Wenn Sie einzelne Komponenten innerhalb Ihrer LLM-App evaluieren möchten, müssen Sie komponentenbasierte Evaluierungen durchführen – eine leistungsstarke Methode zur Bewertung beliebiger Komponenten innerhalb eines LLM-Systems.
Verfolgen Sie einfach "Komponenten" wie LLM-Aufrufe, Retriever, Tool-Aufrufe und Agenten innerhalb Ihrer LLM-Anwendung mit dem @observe-Decorator, um Metriken auf Komponentenebene anzuwenden. Die Verfolgung mit deepeval ist nicht-invasiv (mehr dazu hier) und hilft Ihnen, Ihr Codebase nicht nur für Evaluierungen umschreiben zu müssen:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
Alles über komponentenbasierte Evaluierungen erfahren Sie hier.
Evaluierung ohne Pytest-Integration
Alternativ können Sie auch ohne Pytest evaluieren, was besser für eine Notebook-Umgebung geeignet ist.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
Verwendung eigenständiger Metriken
DeepEval ist extrem modular, sodass jeder unsere Metriken einfach verwenden kann. Fortsetzung des vorherigen Beispiels:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
Beachten Sie, dass einige Metriken für RAG-Pipelines gedacht sind, während andere für Fine-Tuning vorgesehen sind. Stellen Sie sicher, dass Sie unsere Dokumentation verwenden, um die richtige für Ihren Anwendungsfall auszuwählen.
Evaluierung eines Datensatzes / von Testfällen im Bulk
In DeepEval ist ein Datensatz einfach eine Sammlung von Testfällen. So können Sie diese im Bulk evaluieren:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
Alternativ, obwohl wir die Verwendung von deepeval test run empfehlen, können Sie einen Datensatz/Testfälle auch ohne unsere Pytest-Integration evaluieren:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
LLM-Evaluierung mit Confident AI
Der korrekte LLM-Evaluierungslebenszyklus ist nur mit der DeepEval-Plattform erreichbar. Sie ermöglicht Ihnen:
- Kuratieren/Annotieren von Evaluierungsdatensätzen in der Cloud
- Benchmarking der LLM-App mit Datensätzen und Vergleich mit früheren Iterationen, um zu experimentieren, welche Modelle/Prompts am besten funktionieren
- Feinabstimmung von Metriken für benutzerdefinierte Ergebnisse
- Debugging von Evaluierungsergebnissen über LLM-Traces
- Überwachung & Evaluierung von LLM-Antworten im Produkt, um Datensätze mit realen Daten zu verbessern
- Wiederholen bis zur Perfektion
Alles über Confident AI, einschließlich der Verwendung von Confident, finden Sie hier.
Um zu beginnen, melden Sie sich über die CLI an:
deepeval login
Folgen Sie den Anweisungen, um sich anzumelden, Ihr Konto zu erstellen und Ihren API-Schlüssel in die CLI einzufügen.
Führen Sie nun Ihre Testdatei erneut aus:
deepeval test run test_chatbot.py
Nach Abschluss des Tests sollte ein Link in der CLI angezeigt werden. Fügen Sie ihn in Ihren Browser ein, um die Ergebnisse anzuzeigen!
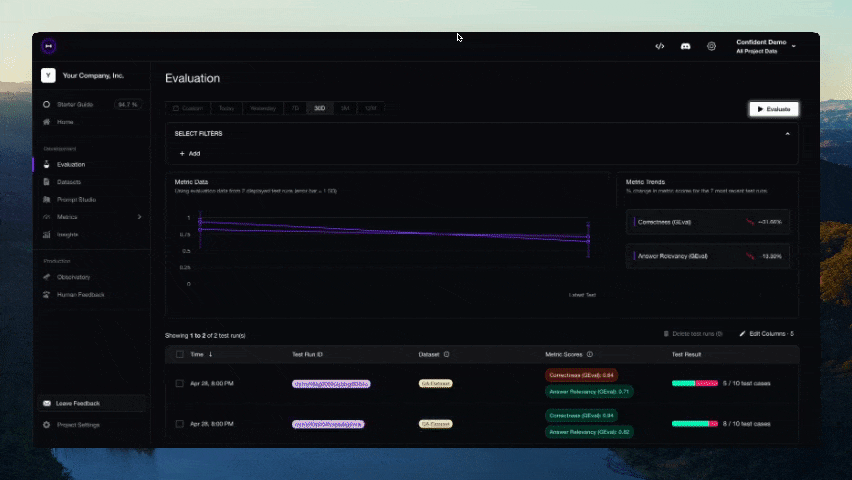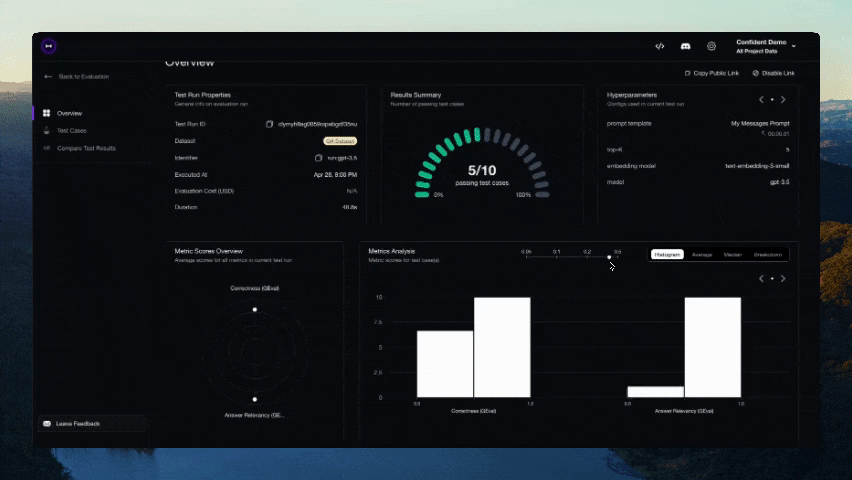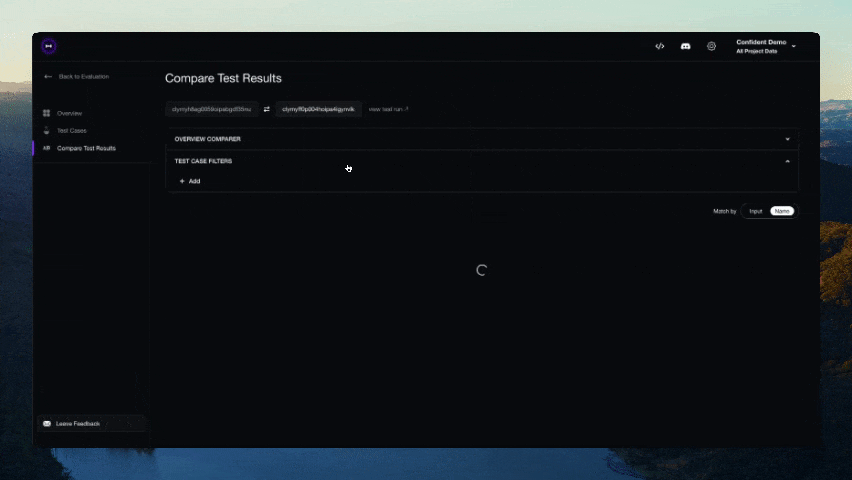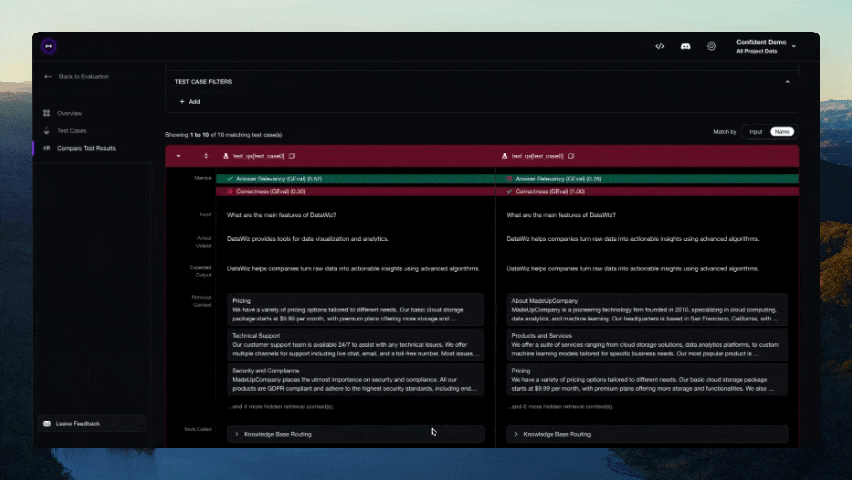
Mitwirken
Bitte lesen Sie CONTRIBUTING.md für Details zu unserem Verhaltenskodex und dem Prozess für die Einreichung von Pull Requests.
Roadmap
Funktionen:
- Integration mit Confident AI
- Implementierung von G-Eval
- Implementierung von RAG-Metriken
- Implementierung von Konversationsmetriken
- Erstellung von Evaluierungsdatensätzen
- Red-Teaming
- DAG-benutzerdefinierte Metriken
- Guardrails
Autoren
Erstellt von den Gründern von Confident AI. Kontaktieren Sie [email protected] für alle Anfragen.
Lizenz
DeepEval ist unter Apache 2.0 lizenziert – siehe die Datei LICENSE.md für Details.