
O Framework de Avaliação de LLM
Documentação | Métricas e Recursos | Primeiros Passos | Integrações | Plataforma DeepEval

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval é um framework de avaliação de LLM (Large Language Models) de código aberto e fácil de usar, projetado para avaliar e testar sistemas baseados em modelos de linguagem grandes. É semelhante ao Pytest, mas especializado em testes unitários de saídas de LLM. O DeepEval incorpora as pesquisas mais recentes para avaliar saídas de LLM com base em métricas como G-Eval, alucinação, relevância da resposta, RAGAS, etc., utilizando LLMs e vários outros modelos de NLP que são executados localmente na sua máquina para avaliação.
Se suas aplicações de LLM são pipelines RAG, chatbots, agentes de IA, implementados via LangChain ou LlamaIndex, o DeepEval tem você coberto. Com ele, você pode facilmente determinar os modelos, prompts e arquitetura ideais para melhorar seu pipeline RAG, fluxos de trabalho agenticos, prevenir deriva de prompt ou até mesmo migrar do OpenAI para hospedar seu próprio Deepseek R1 com confiança.
[!IMPORTANT] Precisa de um lugar para armazenar seus dados de teste do DeepEval 🏡❤️? Cadastre-se na plataforma DeepEval para comparar iterações do seu aplicativo LLM, gerar e compartilhar relatórios de teste e muito mais.
Quer conversar sobre avaliação de LLM, precisa de ajuda para escolher métricas ou apenas dizer olá? Junte-se ao nosso Discord.
🔥 Métricas e Recursos
🥳 Agora você pode compartilhar os resultados de teste do DeepEval diretamente na nuvem usando a infraestrutura do Confident AI
- Suporte para avaliação de LLM tanto em nível de ponta a ponta quanto de componentes.
- Grande variedade de métricas de avaliação de LLM prontas para uso (todas com explicações) alimentadas por QUALQUER LLM de sua escolha, métodos estatísticos ou modelos de NLP que são executados localmente na sua máquina:
- G-Eval
- DAG (grafo acíclico direcionado)
- Métricas RAG:
- Relevância da Resposta
- Fidelidade
- Recall Contextual
- Precisão Contextual
- Relevância Contextual
- RAGAS
- Métricas Agenticas:
- Conclusão de Tarefa
- Correção de Ferramenta
- Outros:
- Alucinação
- Sumarização
- Viés
- Toxicidade
- Métricas Conversacionais:
- Retenção de Conhecimento
- Completude da Conversa
- Relevância da Conversa
- Adequação ao Papel
- etc.
- Crie suas próprias métricas personalizadas que são automaticamente integradas ao ecossistema do DeepEval.
- Gere conjuntos de dados sintéticos para avaliação.
- Integra-se perfeitamente com QUALQUER ambiente CI/CD.
- Faça red teaming do seu aplicativo LLM para mais de 40 vulnerabilidades de segurança com poucas linhas de código, incluindo:
- Toxicidade
- Viés
- Injeção SQL
- etc., usando mais de 10 estratégias avançadas de aprimoramento de ataques, como injeções de prompt.
- Facilmente compare QUALQUER LLM em benchmarks populares de LLM em menos de 10 linhas de código., que incluem:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% integrado com o Confident AI para o ciclo de vida completo de avaliação:
- Curadoria/anotação de conjuntos de dados de avaliação na nuvem
- Benchmark do aplicativo LLM usando conjuntos de dados e comparação com iterações anteriores para experimentar quais modelos/prompts funcionam melhor
- Ajuste fino de métricas para resultados personalizados
- Depuração de resultados de avaliação via traces de LLM
- Monitore e avalie respostas de LLM em produção para melhorar conjuntos de dados com dados do mundo real
- Repita até a perfeição
[!NOTE] Confident AI é a plataforma DeepEval. Crie uma conta aqui.
🔌 Integrações
- 🦄 LlamaIndex, para testar unitariamente aplicações RAG em CI/CD
- 🤗 Hugging Face, para habilitar avaliações em tempo real durante o fine-tuning de LLM
🚀 Primeiros Passos
Vamos supor que seu aplicativo LLM seja um chatbot de suporte ao cliente baseado em RAG; aqui está como o DeepEval pode ajudar a testar o que você construiu.
Instalação
pip install -U deepeval
Crie uma conta (altamente recomendado)
Usar a plataforma deepeval permitirá que você gere relatórios de teste compartilháveis na nuvem. É gratuito, não requer código adicional para configurar e recomendamos fortemente experimentá-la.
Para fazer login, execute:
deepeval login
Siga as instruções no CLI para criar uma conta, copie sua chave de API e cole-a no CLI. Todos os casos de teste serão automaticamente registrados (encontre mais informações sobre privacidade de dados aqui).
Escrevendo seu primeiro caso de teste
Crie um arquivo de teste:
touch test_chatbot.py
Abra test_chatbot.py e escreva seu primeiro caso de teste para executar uma avaliação ponta a ponta usando o DeepEval, que trata seu aplicativo LLM como uma caixa-preta:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
Defina sua OPENAI_API_KEY como uma variável de ambiente (você também pode avaliar usando seu próprio modelo personalizado, para mais detalhes visite esta parte da nossa documentação):
export OPENAI_API_KEY="..."
E finalmente, execute test_chatbot.py no CLI:
deepeval test run test_chatbot.py
Parabéns! Seu caso de teste deve ter passado ✅ Vamos detalhar o que aconteceu.
- A variável
inputsimula uma entrada do usuário, eactual_outputé um placeholder para o que seu aplicativo deve gerar com base nessa entrada. - A variável
expected_outputrepresenta a resposta ideal para um determinadoinput, eGEvalé uma métrica baseada em pesquisa fornecida pelodeepevalpara avaliar as saídas do seu LLM em qualquer critério personalizado com precisão semelhante à humana. - Neste exemplo, o
criteriada métrica é a correção doactual_outputcom base noexpected_outputfornecido. - Todas as pontuações das métricas variam de 0 a 1, onde o
threshold=0.5determina se seu teste passou ou não.
Leia nossa documentação para mais informações sobre opções adicionais para executar avaliações ponta a ponta, como usar métricas adicionais, criar suas próprias métricas personalizadas e tutoriais sobre como integrar com outras ferramentas como LangChain e LlamaIndex.
Avaliando Componentes Aninhados
Se desejar avaliar componentes individuais dentro do seu aplicativo LLM, você precisa executar avaliações em nível de componente - uma maneira poderosa de avaliar qualquer componente dentro de um sistema LLM.
Simplesmente trace "componentes" como chamadas de LLM, recuperadores, chamadas de ferramentas e agentes dentro do seu aplicativo LLM usando o decorador @observe para aplicar métricas em nível de componente. O rastreamento com deepeval é não intrusivo (saiba mais aqui) e ajuda você a evitar reescrever sua base de código apenas para avaliações:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
Você pode aprender tudo sobre avaliações em nível de componente aqui.
Avaliando Sem Integração com Pytest
Alternativamente, você pode avaliar sem o Pytest, o que é mais adequado para um ambiente de notebook.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
Usando Métricas Independentes
O DeepEval é extremamente modular, tornando fácil para qualquer pessoa usar qualquer uma de nossas métricas. Continuando do exemplo anterior:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
Observe que algumas métricas são para pipelines RAG, enquanto outras são para fine-tuning. Certifique-se de usar nossa documentação para escolher a métrica certa para o seu caso de uso.
Avaliando um Conjunto de Dados / Casos de Teste em Massa
No DeepEval, um conjunto de dados é simplesmente uma coleção de casos de teste. Aqui está como você pode avaliá-los em massa:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
Alternativamente, embora recomendemos usar deepeval test run, você pode avaliar um conjunto de dados/casos de teste sem usar nossa integração com Pytest:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Avaliação de LLM com Confident AI
O ciclo de vida correto de avaliação de LLM só é alcançável com a plataforma DeepEval. Ela permite que você:
- Faça curadoria/anotação de conjuntos de dados de avaliação na nuvem
- Faça benchmark do aplicativo LLM usando conjuntos de dados e compare com iterações anteriores para experimentar quais modelos/prompts funcionam melhor
- Ajuste fino de métricas para resultados personalizados
- Depure resultados de avaliação via traces de LLM
- Monitore e avalie respostas de LLM em produção para melhorar conjuntos de dados com dados do mundo real
- Repita até a perfeição
Tudo sobre o Confident AI, incluindo como usar o Confident, está disponível aqui.
Para começar, faça login a partir do CLI:
deepeval login
Siga as instruções para fazer login, criar sua conta e cole sua chave de API no CLI.
Agora, execute seu arquivo de teste novamente:
deepeval test run test_chatbot.py
Você deve ver um link exibido no CLI assim que o teste terminar de ser executado. Cole-o no seu navegador para visualizar os resultados!
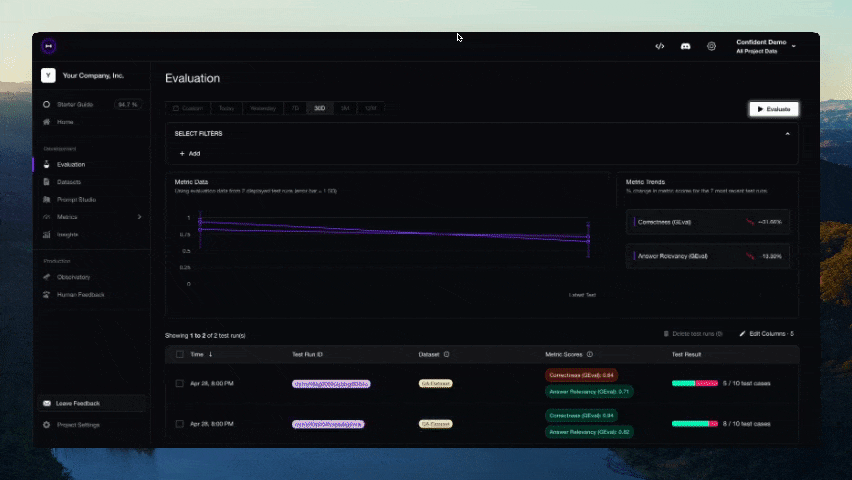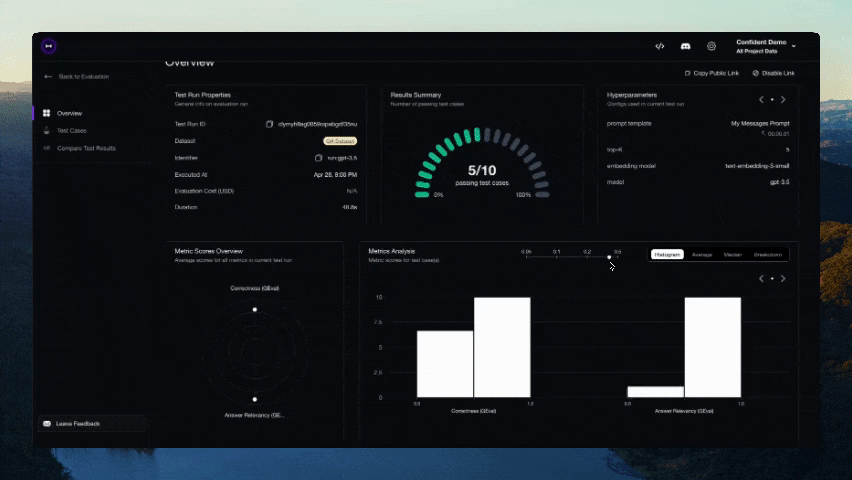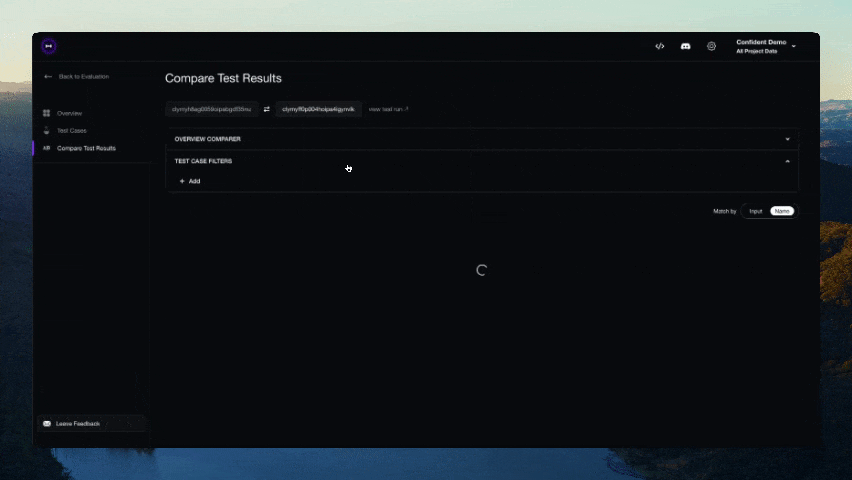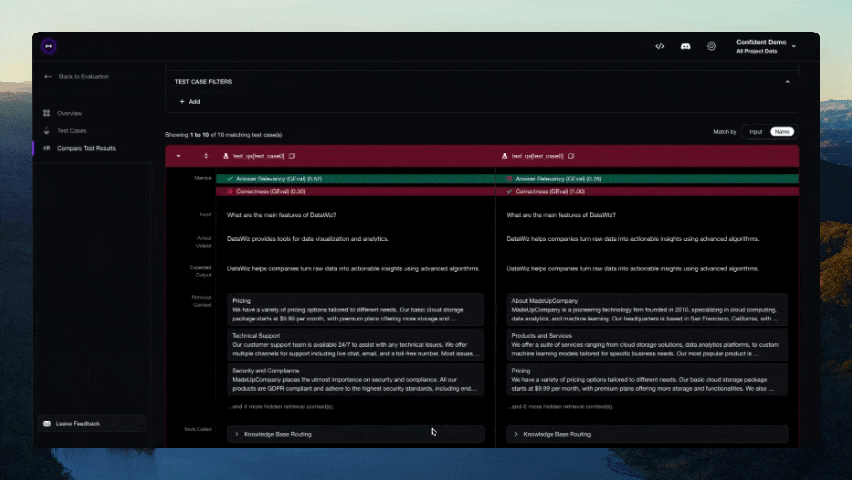
Contribuindo
Por favor, leia CONTRIBUTING.md para detalhes sobre nosso código de conduta e o processo para enviar pull requests para nós.
Roadmap
Recursos:
- Integração com Confident AI
- Implementação do G-Eval
- Implementação de métricas RAG
- Implementação de métricas conversacionais
- Criação de Conjunto de Dados de Avaliação
- Red-Teaming
- Métricas personalizadas DAG
- Guardrails
Autores
Construído pelos fundadores do Confident AI. Contate [email protected] para todas as consultas.
Licença
DeepEval é licenciado sob Apache 2.0 - veja o arquivo LICENSE.md para detalhes.