
Framework d'Évaluation des LLM
Documentation | Métriques et Fonctionnalités | Démarrage Rapide | Intégrations | Plateforme DeepEval

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval est un framework open-source simple d'utilisation pour évaluer et tester les systèmes basés sur des modèles de langage (LLM). Similaire à Pytest mais spécialisé pour les tests unitaires des sorties LLM. DeepEval intègre les dernières recherches pour évaluer les sorties LLM selon des métriques comme G-Eval, hallucination, pertinence de réponse, RAGAS, etc., utilisant des LLMs et divers autres modèles NLP qui s'exécutent localement sur votre machine.
Que vos applications LLM soient des pipelines RAG, chatbots, agents IA, implémentés via LangChain ou LlamaIndex, DeepEval est fait pour vous. Avec lui, vous pouvez facilement déterminer les modèles, prompts et architectures optimaux pour améliorer votre pipeline RAG, workflows agentiques, prévenir la dérive des prompts, ou même passer d'OpenAI à héberger votre propre Deepseek R1 en toute confiance.
[!IMPORTANT] Besoin d'un espace pour stocker vos données de test DeepEval 🏡❤️ ? Inscrivez-vous sur la plateforme DeepEval pour comparer les itérations de votre application LLM, générer et partager des rapports de test, et plus encore.
Vous souhaitez discuter d'évaluation LLM, obtenir de l'aide pour choisir des métriques, ou simplement dire bonjour ? Rejoignez notre Discord.
🔥 Métriques et Fonctionnalités
🥳 Vous pouvez désormais partager les résultats des tests DeepEval directement sur le cloud via Confident AI
- Prise en charge des évaluations LLM de bout en bout et par composant.
- Grande variété de métriques d'évaluation LLM prêtes à l'emploi (toutes expliquées) utilisant N'IMPORTE QUEL LLM de votre choix, méthodes statistiques ou modèles NLP exécutés localement sur votre machine :
- G-Eval
- DAG (graphe acyclique profond)
- Métriques RAG :
- Pertinence de la Réponse
- Fidélité
- Rappel Contextuel
- Précision Contextuelle
- Pertinence Contextuelle
- RAGAS
- Métriques Agentiques :
- Achèvement de Tâche
- Correction des Outils
- Autres :
- Hallucination
- Résumé
- Biais
- Toxicité
- Métriques Conversationnelles :
- Rétention des Connaissances
- Complétude de la Conversation
- Pertinence de la Conversation
- Adhésion au Rôle
- etc.
- Créez vos propres métriques personnalisées intégrées automatiquement à l'écosystème DeepEval.
- Générez des jeux de données synthétiques pour l'évaluation.
- Intégration transparente avec TOUT environnement CI/CD.
- Testez en rouge votre application LLM pour 40+ vulnérabilités de sécurité en quelques lignes de code, incluant :
- Toxicité
- Biais
- Injection SQL
- etc., en utilisant 10+ stratégies d'attaque avancées comme les injections de prompts.
- Bénéficiez facilement de benchmarks pour N'IMPORTE QUEL LLM sur des benchmarks populaires en moins de 10 lignes de code, incluant :
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% intégré avec Confident AI pour le cycle de vie complet de l'évaluation :
- Créez/annotez des jeux de données d'évaluation sur le cloud
- Benchmarkez votre application LLM en utilisant des jeux de données, et comparez avec les itérations précédentes pour expérimenter quels modèles/prompts fonctionnent le mieux
- Ajustez finement les métriques pour des résultats personnalisés
- Déboguez les résultats d'évaluation via les traces LLM
- Surveillez et évaluez les réponses LLM en production pour améliorer les jeux de données avec des données réelles
- Répétez jusqu'à la perfection
[!NOTE] Confident AI est la plateforme DeepEval. Créez un compte ici.
🔌 Intégrations
- 🦄 LlamaIndex, pour tester unitairement les applications RAG en CI/CD
- 🤗 Hugging Face, pour activer des évaluations en temps réel pendant le fine-tuning des LLM
🚀 Démarrage Rapide
Supposons que votre application LLM soit un chatbot d'assistance client basé sur RAG ; voici comment DeepEval peut aider à tester ce que vous avez construit.
Installation
pip install -U deepeval
Créez un compte (fortement recommandé)
Utiliser la plateforme deepeval vous permettra de générer des rapports de test partageables sur le cloud. C'est gratuit, ne nécessite aucun code supplémentaire, et nous vous recommandons vivement d'essayer.
Pour vous connecter, exécutez :
deepeval login
Suivez les instructions dans le CLI pour créer un compte, copiez votre clé API, et collez-la dans le CLI. Tous les cas de test seront automatiquement enregistrés (plus d'informations sur la confidentialité des données ici).
Écrire votre premier cas de test
Créez un fichier de test :
touch test_chatbot.py
Ouvrez test_chatbot.py et écrivez votre premier cas de test pour exécuter une évaluation de bout en bout avec DeepEval, qui traite votre application LLM comme une boîte noire :
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
Définissez votre OPENAI_API_KEY comme variable d'environnement (vous pouvez aussi évaluer en utilisant votre propre modèle personnalisé, pour plus de détails visitez cette partie de notre documentation) :
export OPENAI_API_KEY="..."
Et enfin, exécutez test_chatbot.py dans le CLI :
deepeval test run test_chatbot.py
Félicitations ! Votre cas de test devrait avoir réussi ✅ Décomposons ce qui s'est passé.
- La variable
inputsimule une entrée utilisateur, etactual_outputest un placeholder pour ce que votre application est censée produire en réponse. - La variable
expected_outputreprésente la réponse idéale pour uninputdonné, etGEvalest une métrique soutenue par la recherche fournie pardeepevalpour évaluer vos sorties LLM sur n'importe quel critère avec une précision quasi-humaine. - Dans cet exemple, le
criteriade la métrique est la justesse deactual_outputpar rapport àexpected_output. - Tous les scores de métriques vont de 0 à 1, et le seuil
threshold=0.5détermine finalement si votre test a réussi ou non.
Lisez notre documentation pour plus d'informations sur les options d'évaluation de bout en bout, l'utilisation de métriques supplémentaires, la création de vos propres métriques personnalisées, et des tutoriels sur l'intégration avec d'autres outils comme LangChain et LlamaIndex.
Évaluation des Composants Emboîtés
Si vous souhaitez évaluer des composants individuels dans votre application LLM, vous devez exécuter des évaluations par composant - une méthode puissante pour évaluer n'importe quel composant d'un système LLM.
Tracez simplement les "composants" comme les appels LLM, retrieveurs, appels d'outils et agents dans votre application LLM en utilisant le décorateur @observe pour appliquer des métriques au niveau composant. Le traçage avec deepeval est non intrusif (en savoir plus ici) et vous évite de réécrire votre codebase juste pour les évaluations :
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
Vous pouvez tout apprendre sur les évaluations par composant ici.
Évaluation Sans Intégration Pytest
Alternativement, vous pouvez évaluer sans Pytest, ce qui est plus adapté à un environnement notebook.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
Utilisation de Métriques Autonomes
DeepEval est extrêmement modulaire, facilitant l'utilisation de n'importe laquelle de nos métriques. En reprenant l'exemple précédent :
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
Notez que certaines métriques sont destinées aux pipelines RAG, tandis que d'autres sont pour le fine-tuning. Assurez-vous d'utiliser notre documentation pour choisir celle adaptée à votre cas d'usage.
Évaluation d'un Jeu de Données / Cas de Test en Masse
Dans DeepEval, un jeu de données est simplement une collection de cas de test. Voici comment les évaluer en masse :
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
Alternativement, bien que nous recommandions deepeval test run, vous pouvez évaluer un jeu de données/cas de test sans utiliser notre intégration Pytest :
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Évaluation LLM Avec Confident AI
Le cycle de vie correct de l'évaluation LLM n'est réalisable qu'avec la plateforme DeepEval. Elle vous permet de :
- Créer/annoter des jeux de données d'évaluation sur le cloud
- Benchmarker votre application LLM en utilisant des jeux de données, et comparer avec les itérations précédentes pour expérimenter quels modèles/prompts fonctionnent le mieux
- Ajuster finement les métriques pour des résultats personnalisés
- Déboguer les résultats d'évaluation via les traces LLM
- Surveiller et évaluer les réponses LLM en production pour améliorer les jeux de données avec des données réelles
- Répéter jusqu'à la perfection
Tout sur Confident AI, y compris son utilisation, est disponible ici.
Pour commencer, connectez-vous depuis le CLI :
deepeval login
Suivez les instructions pour vous connecter, créer votre compte, et collez votre clé API dans le CLI.
Maintenant, exécutez à nouveau votre fichier de test :
deepeval test run test_chatbot.py
Vous devriez voir un lien affiché dans le CLI une fois le test terminé. Collez-le dans votre navigateur pour voir les résultats !
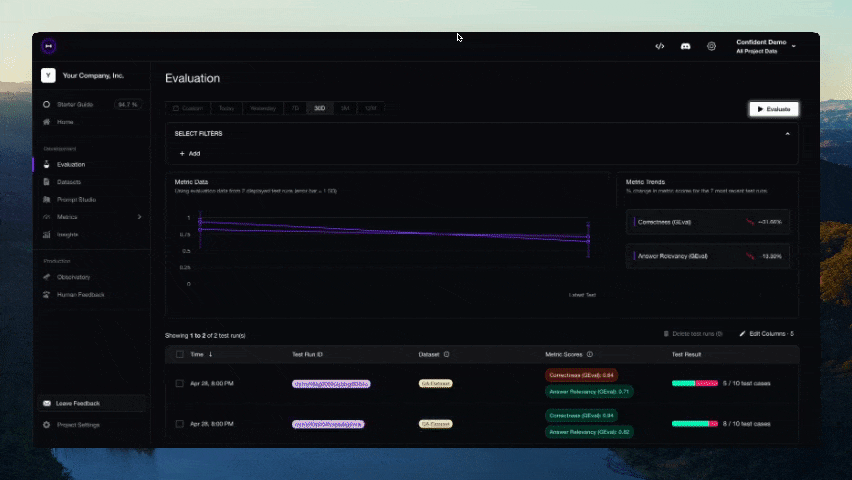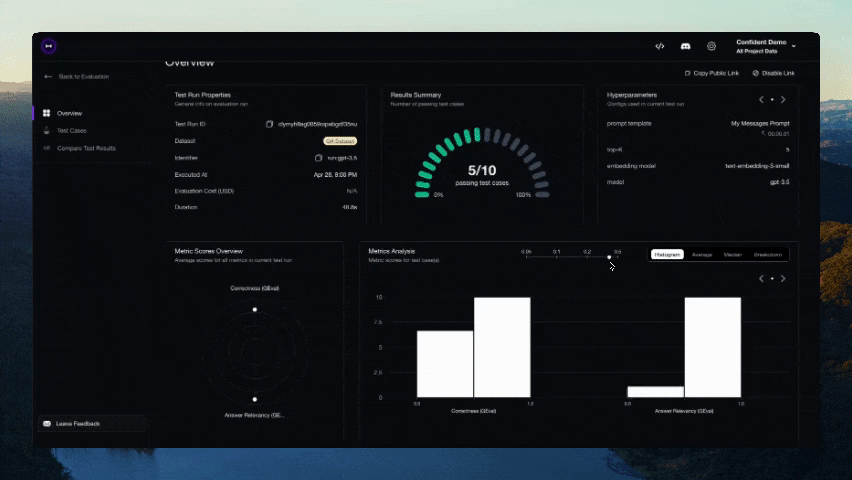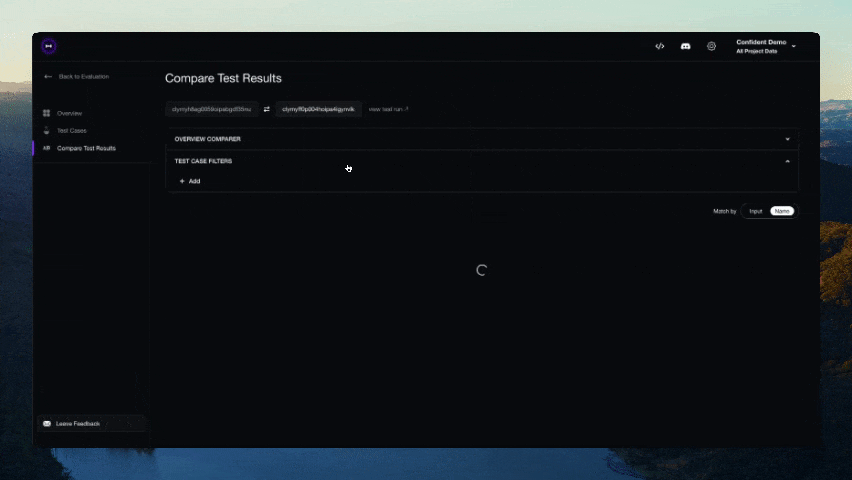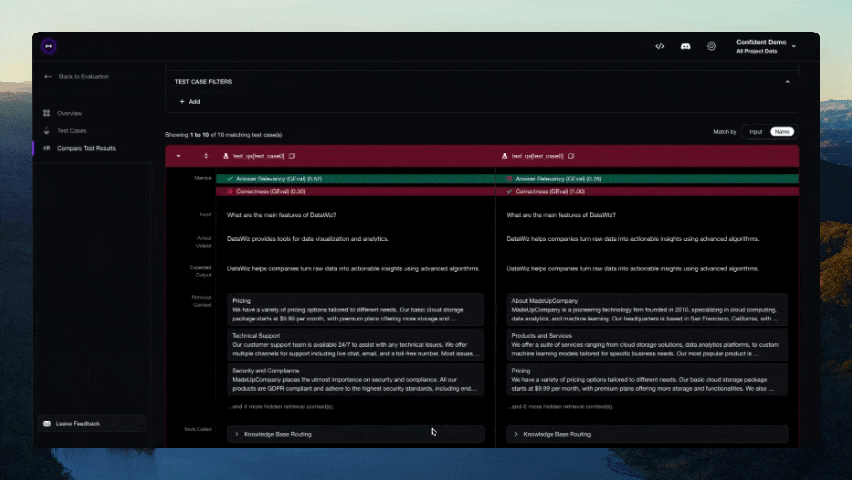
Contributions
Veuillez lire CONTRIBUTING.md pour les détails sur notre code de conduite, et le processus pour soumettre des pull requests.
Feuille de Route
Fonctionnalités :
- Intégration avec Confident AI
- Implémentation de G-Eval
- Implémentation des métriques RAG
- Implémentation des métriques conversationnelles
- Création de jeux de données d'évaluation
- Tests en rouge
- Métriques personnalisées DAG
- Garde-fous
Auteurs
Construit par les fondateurs de Confident AI. Contactez [email protected] pour toute demande.
Licence
DeepEval est sous licence Apache 2.0 - voir le fichier LICENSE.md pour plus de détails.