
LLM 평가 프레임워크
문서 | 메트릭 및 기능 | 시작하기 | 통합 | DeepEval 플랫폼

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval는 대규모 언어 모델 시스템을 평가하고 테스트하기 위한 사용하기 쉬운 오픈소스 LLM 평가 프레임워크입니다. Pytest와 유사하지만 LLM 출력을 단위 테스트하는 데 특화되어 있습니다. DeepEval은 G-Eval, 환각(hallucination), 답변 관련성(answer relevancy), RAGAS 등의 메트릭을 기반으로 LLM 출력을 평가하기 위한 최신 연구를 통합하며, 이는 로컬 머신에서 실행되는 LLM 및 다양한 NLP 모델을 사용합니다.
LLM 애플리케이션이 RAG 파이프라인, 챗봇, AI 에이전트이든, LangChain 또는 LlamaIndex로 구현되었든, DeepEval이 지원합니다. 이를 통해 RAG 파이프라인, 에이전트 워크플로우를 개선하고, 프롬프트 드리프트를 방지하거나, OpenAI에서 자체 호스팅하는 Deepseek R1로 전환하는 데 필요한 최적의 모델, 프롬프트 및 아키텍처를 쉽게 결정할 수 있습니다.
[!IMPORTANT] DeepEval 테스트 데이터를 저장할 공간이 필요하신가요 🏡❤️? DeepEval 플랫폼에 가입하세요 — LLM 앱의 반복 비교, 테스트 보고서 생성 및 공유 등을 할 수 있습니다.
LLM 평가에 대해 논의하거나, 메트릭 선택에 도움이 필요하거나, 단순히 인사하고 싶으신가요? 디스코드에 참여하세요.
🔥 메트릭 및 기능
🥳 이제 Confident AI 인프라를 통해 DeepEval 테스트 결과를 클라우드에 직접 공유할 수 있습니다.
- 종단 간(end-to-end) 및 구성 요소 수준(component-level) LLM 평가를 모두 지원합니다.
- 선택한 LLM, 통계적 방법 또는 로컬 머신에서 실행되는 NLP 모델로 구동되는 다양한 즉시 사용 가능한 LLM 평가 메트릭(모두 설명 포함):
- G-Eval
- DAG(deep acyclic graph)
- RAG 메트릭:
- 답변 관련성(Answer Relevancy)
- 신뢰성(Faithfulness)
- 문맥적 회상(Contextual Recall)
- 문맥적 정밀도(Contextual Precision)
- 문맥적 관련성(Contextual Relevancy)
- RAGAS
- 에이전트 메트릭:
- 작업 완료율(Task Completion)
- 도구 정확도(Tool Correctness)
- 기타:
- 환각(Hallucination)
- 요약(Summarization)
- 편향(Bias)
- 유해성(Toxicity)
- 대화 메트릭:
- 지식 보존(Knowledge Retention)
- 대화 완성도(Conversation Completeness)
- 대화 관련성(Conversation Relevancy)
- 역할 준수(Role Adherence)
- 기타
- DeepEval 생태계와 자동으로 통합되는 사용자 정의 메트릭을 구축할 수 있습니다.
- 평가를 위한 합성 데이터셋을 생성합니다.
- 모든 CI/CD 환경과 원활하게 통합됩니다.
- 몇 줄의 코드로 LLM 애플리케이션을 레드팀링하여 40개 이상의 보안 취약점을 테스트할 수 있습니다:
- 유해성(Toxicity)
- 편향(Bias)
- SQL 인젝션(SQL Injection)
- 기타, 프롬프트 인젝션과 같은 10개 이상의 고급 공격 강화 전략 사용.
- 10줄 이하의 코드로 인기 있는 LLM 벤치마크에서 어떤 LLM이든 쉽게 벤치마크할 수 있습니다:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 전체 평가 라이프사이클을 위해 100% Confident AI와 통합:
- 클라우드에서 평가 데이터셋 큐레이션/주석 달기
- 데이터셋을 사용하여 LLM 앱 벤치마크 및 이전 반복과 비교하여 최적의 모델/프롬프트 실험
- 사용자 정의 결과를 위한 메트릭 미세 조정
- LLM 추적을 통해 평가 결과 디버깅
- 제품에서 LLM 응답 모니터링 및 평가하여 실제 데이터로 데이터셋 개선
- 완벽할 때까지 반복
[!NOTE] Confident AI는 DeepEval 플랫폼입니다. 여기에서 계정을 생성하세요.
🔌 통합
- 🦄 LlamaIndex, CI/CD에서 RAG 애플리케이션 단위 테스트
- 🤗 Hugging Face, LLM 미세 조정 중 실시간 평가 활성화
🚀 시작하기
LLM 애플리케이션이 RAG 기반 고객 지원 챗봇이라고 가정하고, DeepEval이 구축한 것을 테스트하는 방법을 알아보겠습니다.
설치
pip install -U deepeval
계정 생성(권장)
deepeval 플랫폼을 사용하면 클라우드에서 공유 가능한 테스트 보고서를 생성할 수 있습니다. 추가 코드 설정이 필요 없으며 무료이므로 꼭 사용해 보시기를 권장합니다.
로그인하려면 다음을 실행하세요:
deepeval login
CLI의 지시에 따라 계정을 생성하고 API 키를 복사하여 CLI에 붙여넣으세요. 모든 테스트 케이스가 자동으로 기록됩니다(데이터 개인정보 보호에 대한 자세한 내용은 여기에서 확인하세요).
첫 번째 테스트 케이스 작성
테스트 파일 생성:
touch test_chatbot.py
test_chatbot.py를 열고 DeepEval을 사용하여 종단 간 평가를 실행하는 첫 번째 테스트 케이스를 작성하세요. 이는 LLM 앱을 블랙박스로 취급합니다:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
OPENAI_API_KEY를 환경 변수로 설정하세요(사용자 정의 모델을 사용하여 평가할 수도 있습니다. 자세한 내용은 문서의 이 부분을 참조하세요):
export OPENAI_API_KEY="..."
마지막으로 CLI에서 test_chatbot.py를 실행하세요:
deepeval test run test_chatbot.py
축하합니다! 테스트 케이스가 통과되었어야 합니다 ✅ 어떤 일이 일어났는지 분석해 보겠습니다.
- 변수
input은 사용자 입력을 모방하고,actual_output은 이 입력을 기반으로 애플리케이션이 출력해야 할 내용을 나타냅니다. - 변수
expected_output은 주어진input에 대한 이상적인 답변을 나타내며,GEval은deepeval이 제공하는 연구 기반 메트릭으로, 인간 수준의 정확도로 LLM 출력을 평가할 수 있습니다. - 이 예에서 메트릭
criteria는 제공된expected_output을 기반으로actual_output의 정확성입니다. - 모든 메트릭 점수는 0 - 1 범위이며,
threshold=0.5임계값이 최종적으로 테스트 통과 여부를 결정합니다.
문서를 읽어보세요 — 종단 간 평가 실행, 추가 메트릭 사용 방법, 사용자 정의 메트릭 생성, LangChain 및 LlamaIndex와 같은 다른 도구와 통합하는 방법에 대한 튜토리얼을 확인할 수 있습니다.
중첩 구성 요소 평가
LLM 앱 내의 개별 구성 요소를 평가하려면 구성 요소 수준 평가를 실행해야 합니다 — LLM 시스템 내의 모든 구성 요소를 평가하는 강력한 방법입니다.
LLM 호출, 검색기(retriever), 도구 호출, 에이전트와 같은 "구성 요소"를 @observe 데코레이터로 추적하여 구성 요소 수준에서 메트릭을 적용하세요. deepeval로 추적하는 것은 비침습적이며(자세한 내용은 여기), 평가를 위해 코드베이스를 재작성할 필요가 없습니다:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
구성 요소 수준 평가에 대한 모든 내용은 여기에서 확인하세요.
Pytest 통합 없이 평가
또는 노트북 환경에 더 적합한 Pytest 없이 평가할 수 있습니다.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
독립형 메트릭 사용
DeepEval은 매우 모듈화되어 있어 누구나 메트릭을 쉽게 사용할 수 있습니다. 이전 예제에서 계속:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
일부 메트릭은 RAG 파이프라인용이고, 다른 메트릭은 미세 조정용입니다. 사용 사례에 맞는 메트릭을 선택하려면 문서를 참조하세요.
데이터셋/테스트 케이스 일괄 평가
DeepEval에서 데이터셋은 단순히 테스트 케이스의 모음입니다. 일괄 평가 방법은 다음과 같습니다:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
또는 deepeval test run을 사용하는 것을 권장하지만, Pytest 통합 없이 데이터셋/테스트 케이스를 평가할 수도 있습니다:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Confident AI로 LLM 평가
올바른 LLM 평가 라이프사이클은 DeepEval 플랫폼으로만 달성할 수 있습니다. 이를 통해 다음을 수행할 수 있습니다:
- 클라우드에서 평가 데이터셋 큐레이션/주석 달기
- 데이터셋을 사용하여 LLM 앱 벤치마크 및 이전 반복과 비교하여 최적의 모델/프롬프트 실험
- 사용자 정의 결과를 위한 메트릭 미세 조정
- LLM 추적을 통해 평가 결과 디버깅
- 제품에서 LLM 응답 모니터링 및 평가하여 실제 데이터로 데이터셋 개선
- 완벽할 때까지 반복
Confident AI의 모든 것, 사용 방법은 여기에서 확인하세요.
시작하려면 CLI에서 로그인하세요:
deepeval login
로그인, 계정 생성, API 키를 CLI에 붙여넣는 지침을 따르세요.
이제 테스트 파일을 다시 실행하세요:
deepeval test run test_chatbot.py
테스트 실행이 완료되면 CLI에 링크가 표시됩니다. 브라우저에 붙여넣어 결과를 확인하세요!
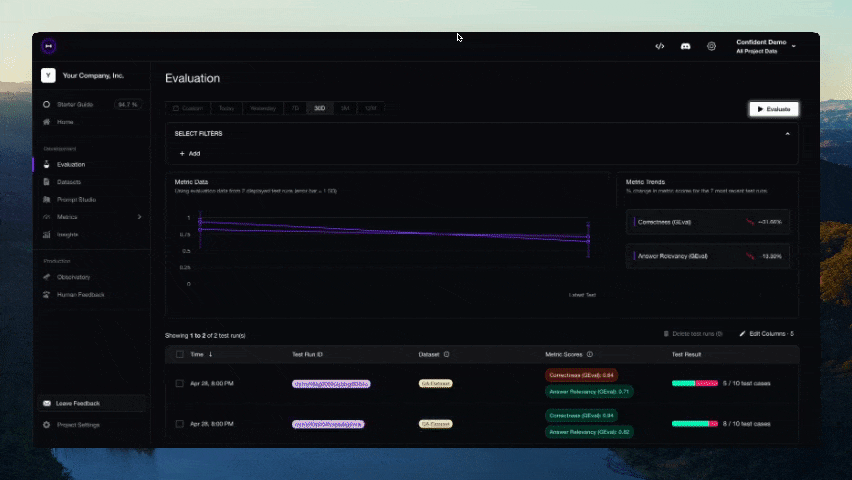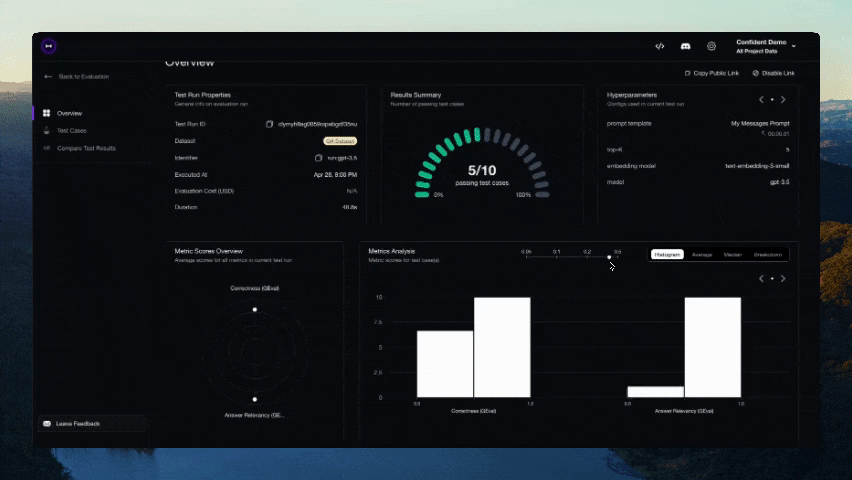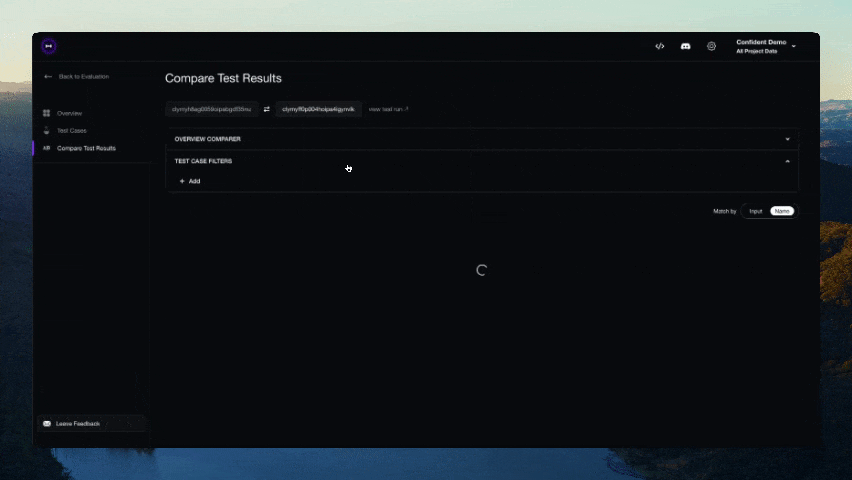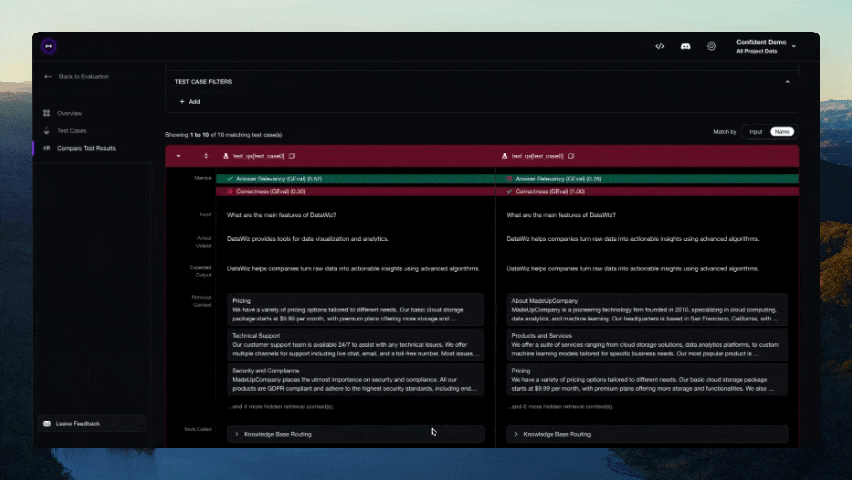
기여
기여 가이드라인은 CONTRIBUTING.md를 참조하세요.
로드맵
기능:
- Confident AI 통합
- G-Eval 구현
- RAG 메트릭 구현
- 대화 메트릭 구현
- 평가 데이터셋 생성
- 레드팀링
- DAG 사용자 정의 메트릭
- 가드레일
저자
Confident AI의 창립자가 구축했습니다. 문의 사항은 [email protected]으로 연락하세요.
라이선스
DeepEval은 Apache 2.0 라이선스로 제공됩니다 — 자세한 내용은 LICENSE.md 파일을 참조하세요.