
LLM評価フレームワーク
ドキュメント | メトリクスと機能 | クイックスタート | インテグレーション | DeepEvalプラットフォーム

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEvalは、大規模言語モデル(LLM)システムを評価・テストするためのシンプルでオープンソースな評価フレームワークです。Pytestに似ていますが、LLM出力のユニットテストに特化しています。DeepEvalは最新の研究を組み込み、G-Eval、Hallucination(幻覚)、Answer Relevancy(回答関連性)、RAGASなどのメトリクスに基づいてLLM出力を評価します。これらはローカルマシン上で動作するLLMや様々なNLPモデルを使用します。
LLMアプリケーションがRAGパイプライン、チャットボット、AIエージェントであっても、LangChainやLlamaIndexで実装されていても、DeepEvalは対応しています。これを使用すれば、最適なモデル、プロンプト、アーキテクチャを簡単に決定し、RAGパイプラインやエージェントワークフローの改善、プロンプトドリフトの防止、OpenAIから独自のDeepseek R1への移行を自信を持って行えます。
[!IMPORTANT] DeepEvalのテストデータを保存する場所が必要ですか 🏡❤️? DeepEvalプラットフォームにサインアップして、LLMアプリのイテレーションを比較し、テストレポートを生成・共有しましょう。
LLM評価について話したい、メトリクスの選び方の助けが必要、またはただ挨拶したいですか? Discordに参加しましょう。
🔥 メトリクスと機能
🥳 Confident AIのインフラ上でDeepEvalのテスト結果を直接クラウドに共有できるようになりました
- エンドツーエンドおよびコンポーネントレベルのLLM評価をサポート
- 任意のLLM、統計手法、またはローカルマシン上で動作するNLPモデルを使用した多様な即時利用可能なLLM評価メトリクス(すべて説明付き):
- G-Eval
- DAG(深層非循環グラフ)
- RAGメトリクス:
- 回答関連性
- 忠実度
- 文脈的再現率
- 文脈的精度
- 文脈的関連性
- RAGAS
- エージェントメトリクス:
- タスク完了率
- ツール正確性
- その他:
- 幻覚
- 要約
- バイアス
- 毒性
- 会話メトリクス:
- 知識保持
- 会話完全性
- 会話関連性
- 役割遵守
- など
- DeepEvalのエコシステムと自動統合されるカスタムメトリクスを構築
- 評価用の合成データセットを生成
- 任意のCI/CD環境とシームレスに統合
- 数行のコードでLLMアプリケーションをレッドチーミングし、40以上のセキュリティ脆弱性をテスト:
- 毒性
- バイアス
- SQLインジェクション
- など、プロンプトインジェクションを含む10以上の高度な攻撃強化戦略を使用
- 10行未満のコードで人気のLLMベンチマークで任意のLLMを簡単にベンチマーク:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- Confident AIと100%統合した完全な評価ライフサイクル:
- クラウド上で評価データセットをキュレート/アノテート
- データセットを使用してLLMアプリをベンチマークし、以前のイテレーションと比較して最適なモデル/プロンプトを実験
- カスタム結果のためにメトリクスを微調整
- LLMトレースで評価結果をデバッグ
- 製品内でLLM応答を監視・評価し、実世界のデータでデータセットを改善
- 完璧になるまで繰り返し
[!NOTE] Confident AIはDeepEvalプラットフォームです。こちらからアカウントを作成してください。
🔌 インテグレーション
- 🦄 LlamaIndex、CI/CDでRAGアプリケーションをユニットテスト
- 🤗 Hugging Face、LLMファインチューニング中のリアルタイム評価を有効化
🚀 クイックスタート
LLMアプリケーションがRAGベースのカスタマーサポートチャットボットだと仮定して、DeepEvalが構築したものをテストする方法を説明します。
インストール
pip install -U deepeval
アカウント作成(強く推奨)
deepevalプラットフォームを使用すると、クラウド上で共有可能なテストレポートを生成できます。無料で、追加のコードは不要です。ぜひお試しください。
ログインするには、以下を実行:
deepeval login
CLIの指示に従ってアカウントを作成し、APIキーをコピーしてCLIに貼り付けます。すべてのテストケースが自動的に記録されます(データプライバシーの詳細はこちら)。
最初のテストケースを作成
テストファイルを作成:
touch test_chatbot.py
test_chatbot.pyを開き、DeepEvalを使用してエンドツーエンド評価を実行する最初のテストケースを作成します。これはLLMアプリをブラックボックスとして扱います:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
OPENAI_API_KEYを環境変数として設定(カスタムモデルを使用して評価することも可能です。詳細はドキュメントのこの部分を参照):
export OPENAI_API_KEY="..."
最後に、CLIでtest_chatbot.pyを実行:
deepeval test run test_chatbot.py
おめでとうございます!テストケースは合格しているはずです ✅ 何が起こったのかを分解してみましょう。
- 変数
inputはユーザー入力を模倣し、actual_outputはこの入力に基づいてアプリケーションが出力すべきもののプレースホルダーです。 - 変数
expected_outputは与えられたinputに対する理想的な回答を表し、GEvalはdeepevalが提供する研究に基づいたメトリクスで、人間のような精度でLLM出力を任意のカスタム基準で評価できます。 - この例では、メトリクス
criteriaは提供されたexpected_outputに基づくactual_outputの正確性です。 - すべてのメトリクススコアは0~1の範囲で、
threshold=0.5の閾値がテストの合格/不合格を最終的に決定します。
ドキュメントを読むことで、エンドツーエンド評価を実行するための追加オプション、追加メトリクスの使用方法、カスタムメトリクスの作成、LangChainやLlamaIndexなどの他のツールとの統合方法に関するチュートリアルを確認できます。
ネストされたコンポーネントの評価
LLMアプリ内の個々のコンポーネントを評価したい場合は、コンポーネントレベルの評価を実行する必要があります - LLMシステム内の任意のコンポーネントを評価する強力な方法です。
@observeデコレータを使用してLLM呼び出し、リトリーバー、ツール呼び出し、エージェントなどの「コンポーネント」をトレースし、コンポーネントレベルでメトリクスを適用します。deepevalによるトレースは非侵入的です(詳細はこちら)評価のためにコードベースを書き直す必要がありません:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
コンポーネントレベルの評価についてすべて学ぶにはこちらを参照してください。
Pytest統合なしでの評価
別の方法として、Pytestを使用せずに評価することも可能で、ノートブック環境により適しています。
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
スタンドアロンメトリクスの使用
DeepEvalは非常にモジュール化されており、誰でも簡単にメトリクスを使用できます。前の例から続けて:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
一部のメトリクスはRAGパイプライン用、他のものはファインチューニング用であることに注意してください。ユースケースに適したものを選ぶためにドキュメントを参照してください。
データセット/テストケースの一括評価
DeepEvalでは、データセットは単にテストケースのコレクションです。以下はそれらを一括評価する方法です:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
あるいは、deepeval test runを使用することを推奨しますが、Pytest統合を使用せずにデータセット/テストケースを評価することも可能です:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Confident AIによるLLM評価
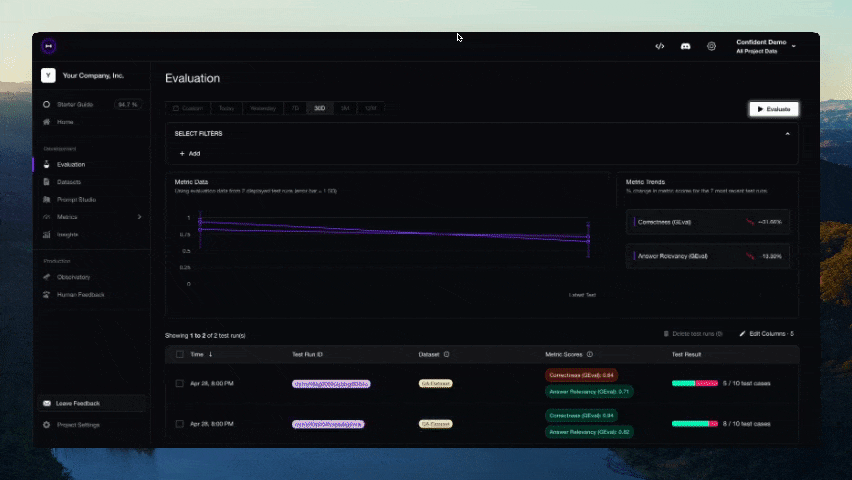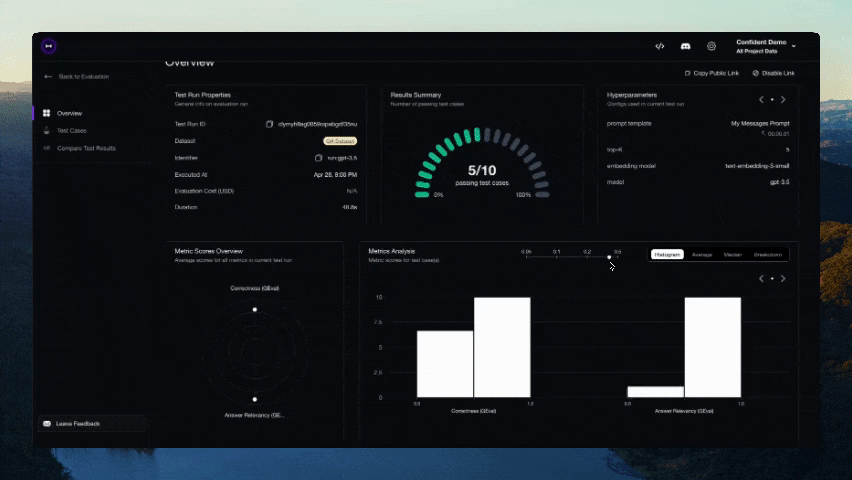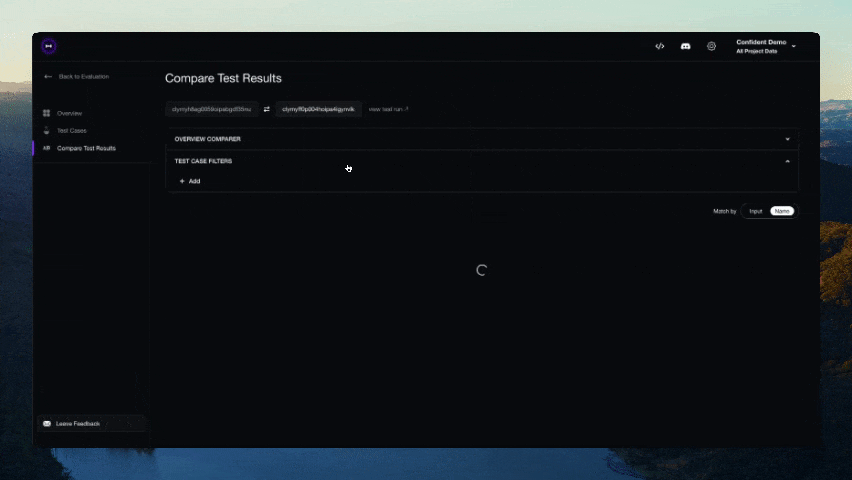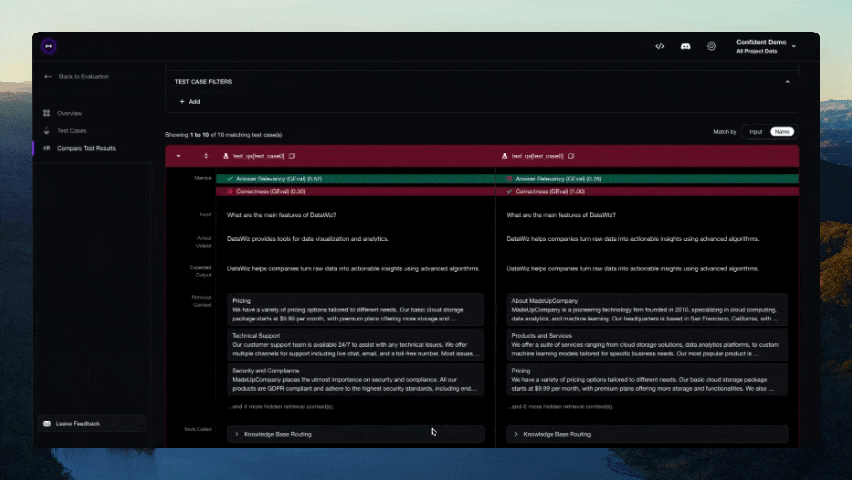
正しいLLM評価ライフサイクルは、DeepEvalプラットフォームでのみ実現可能です。これにより以下が可能です:
- クラウド上で評価データセットをキュレート/アノテート
- データセットを使用してLLMアプリをベンチマークし、以前のイテレーションと比較して最適なモデル/プロンプトを実験
- カスタム結果のためにメトリクスを微調整
- LLMトレースで評価結果をデバッグ
- 製品内でLLM応答を監視・評価し、実世界のデータでデータセットを改善
- 完璧になるまで繰り返し
Confident AIのすべて、Confidentの使用方法はこちらで利用可能です。
開始するには、CLIからログイン:
deepeval login
指示に従ってログインし、アカウントを作成し、APIキーをCLIに貼り付けます。
次に、テストファイルを再度実行:
deepeval test run test_chatbot.py
テストの実行が完了すると、CLIにリンクが表示されます。ブラウザに貼り付けて結果を確認しましょう!
貢献
行動規範とプルリクエストのプロセスについては、CONTRIBUTING.mdをお読みください。
ロードマップ
機能:
- Confident AIとの統合
- G-Evalの実装
- RAGメトリクスの実装
- 会話メトリクスの実装
- 評価データセット作成
- レッドチーミング
- DAGカスタムメトリクス
- ガードレール
著者
Confident AIの創設者によって構築されました。すべての問い合わせは[email protected]まで。
ライセンス
DeepEvalはApache 2.0ライセンスの下で提供されています - 詳細はLICENSE.mdファイルを参照してください。