
El Marco de Evaluación para LLMs
Documentación | Métricas y Características | Primeros Pasos | Integraciones | Plataforma DeepEval

![]()

Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval es un marco de evaluación de LLMs de código abierto y fácil de usar, diseñado para evaluar y probar sistemas de modelos de lenguaje grandes. Es similar a Pytest pero especializado en pruebas unitarias de salidas de LLMs. DeepEval incorpora las últimas investigaciones para evaluar salidas de LLMs basándose en métricas como G-Eval, alucinaciones, relevancia de respuestas, RAGAS, etc., utilizando LLMs y varios otros modelos NLP que se ejecutan localmente en tu máquina para la evaluación.
Ya sea que tus aplicaciones de LLM sean pipelines RAG, chatbots, agentes de IA, implementados mediante LangChain o LlamaIndex, DeepEval te cubre. Con él, puedes determinar fácilmente los modelos, prompts y arquitectura óptimos para mejorar tu pipeline RAG, flujos de trabajo agentes, prevenir el desvío de prompts o incluso hacer la transición de OpenAI a alojar tu propio Deepseek R1 con confianza.
[!IMPORTANT] ¿Necesitas un lugar para almacenar tus datos de prueba de DeepEval 🏡❤️? Regístrate en la plataforma DeepEval para comparar iteraciones de tu aplicación LLM, generar y compartir informes de prueba, y más.
¿Quieres hablar sobre evaluación de LLMs, necesitas ayuda eligiendo métricas o simplemente saludar? Únete a nuestro Discord.
🔥 Métricas y Características
🥳 Ahora puedes compartir los resultados de las pruebas de DeepEval en la nube directamente en la infraestructura de Confident AI
- Soporta evaluación de LLMs tanto de extremo a extremo como a nivel de componentes.
- Gran variedad de métricas de evaluación de LLMs listas para usar (todas con explicaciones) impulsadas por CUALQUIER LLM de tu elección, métodos estadísticos o modelos NLP que se ejecutan localmente en tu máquina:
- G-Eval
- DAG (grafo acíclico dirigido)
- Métricas RAG:
- Relevancia de la Respuesta
- Fidelidad
- Recuerdo Contextual
- Precisión Contextual
- Relevancia Contextual
- RAGAS
- Métricas Agenticas:
- Finalización de Tareas
- Corrección de Herramientas
- Otras:
- Alucinación
- Resumen
- Sesgo
- Toxicidad
- Métricas Conversacionales:
- Retención de Conocimiento
- Completitud de la Conversación
- Relevancia de la Conversación
- Adherencia al Rol
- etc.
- Construye tus propias métricas personalizadas que se integran automáticamente con el ecosistema de DeepEval.
- Genera conjuntos de datos sintéticos para evaluación.
- Se integra perfectamente con CUALQUIER entorno CI/CD.
- Red teaming para tu aplicación LLM para más de 40 vulnerabilidades de seguridad en pocas líneas de código, incluyendo:
- Toxicidad
- Sesgo
- Inyección SQL
- etc., utilizando más de 10 estrategias avanzadas de mejora de ataques como inyecciones de prompts.
- Fácilmente compara CUALQUIER LLM en benchmarks populares de LLMs en menos de 10 líneas de código., que incluyen:
- MMLU
- HellaSwag
- DROP
- BIG-Bench Hard
- TruthfulQA
- HumanEval
- GSM8K
- 100% integrado con Confident AI para el ciclo de vida completo de evaluación:
- Curar/etiquetar conjuntos de datos de evaluación en la nube
- Comparar aplicaciones LLM usando conjuntos de datos, y comparar con iteraciones anteriores para experimentar qué modelos/prompts funcionan mejor
- Ajustar métricas para resultados personalizados
- Depurar resultados de evaluación mediante trazas LLM
- Monitorear y evaluar respuestas LLM en producción para mejorar conjuntos de datos con datos del mundo real
- Repetir hasta la perfección
[!NOTE] Confident AI es la plataforma DeepEval. Crea una cuenta aquí.
🔌 Integraciones
- 🦄 LlamaIndex, para pruebas unitarias de aplicaciones RAG en CI/CD
- 🤗 Hugging Face, para habilitar evaluaciones en tiempo real durante el fine-tuning de LLMs
🚀 Primeros Pasos
Supongamos que tu aplicación LLM es un chatbot de soporte al cliente basado en RAG; aquí te mostramos cómo DeepEval puede ayudar a probar lo que has construido.
Instalación
pip install -U deepeval
Crear una cuenta (altamente recomendado)
Usar la plataforma deepeval te permitirá generar informes de prueba compartibles en la nube. Es gratuito, no requiere código adicional para configurarlo y recomendamos encarecidamente probarlo.
Para iniciar sesión, ejecuta:
deepeval login
Sigue las instrucciones en la CLI para crear una cuenta, copiar tu API key y pegarla en la CLI. Todos los casos de prueba se registrarán automáticamente (encuentra más información sobre privacidad de datos aquí).
Escribiendo tu primer caso de prueba
Crea un archivo de prueba:
touch test_chatbot.py
Abre test_chatbot.py y escribe tu primer caso de prueba para ejecutar una evaluación de extremo a extremo usando DeepEval, que trata tu aplicación LLM como una caja negra:
import pytest
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
def test_case():
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the 'actual output' is correct based on the 'expected output'.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="You have 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
Configura tu OPENAI_API_KEY como una variable de entorno (también puedes evaluar usando tu propio modelo personalizado, para más detalles visita esta parte de nuestra documentación):
export OPENAI_API_KEY="..."
Y finalmente, ejecuta test_chatbot.py en la CLI:
deepeval test run test_chatbot.py
¡Felicidades! Tu caso de prueba debería haber pasado ✅ Vamos a desglosar lo que sucedió.
- La variable
inputsimula una entrada de usuario, yactual_outputes un marcador de posición para lo que se supone que debe generar tu aplicación basada en esta entrada. - La variable
expected_outputrepresenta la respuesta ideal para unainputdada, yGEvales una métrica respaldada por investigación proporcionada pordeepevalpara que evalúes las salidas de tu LLM en cualquier criterio personalizado con precisión similar a la humana. - En este ejemplo, el
criteriade la métrica es la corrección delactual_outputbasado en elexpected_outputproporcionado. - Todos los puntajes de las métricas van de 0 a 1, donde el umbral
threshold=0.5determina finalmente si tu prueba ha pasado o no.
Lee nuestra documentación para más información sobre más opciones para ejecutar evaluaciones de extremo a extremo, cómo usar métricas adicionales, crear tus propias métricas personalizadas y tutoriales sobre cómo integrarte con otras herramientas como LangChain y LlamaIndex.
Evaluando Componentes Anidados
Si deseas evaluar componentes individuales dentro de tu aplicación LLM, necesitas ejecutar evaluaciones a nivel de componentes, una forma poderosa de evaluar cualquier componente dentro de un sistema LLM.
Simplemente traza "componentes" como llamadas LLM, recuperadores, llamadas a herramientas y agentes dentro de tu aplicación LLM usando el decorador @observe para aplicar métricas a nivel de componente. El trazado con deepeval no es intrusivo (aprende más aquí) y te ayuda a evitar reescribir tu base de código solo para evaluaciones:
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase
from deepeval.dataset import Golden
from deepeval.metrics import GEval
from deepeval import evaluate
correctness = GEval(name="Correctness", criteria="Determine if the 'actual output' is correct based on the 'expected output'.", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT])
@observe(metrics=[correctness])
def inner_component():
# Component can be anything from an LLM call, retrieval, agent, tool use, etc.
update_current_span(test_case=LLMTestCase(input="...", actual_output="..."))
return
@observe
def llm_app(input: str):
inner_component()
return
evaluate(observed_callback=llm_app, goldens=[Golden(input="Hi!")])
Puedes aprender todo sobre evaluaciones a nivel de componentes aquí.
Evaluando Sin Integración con Pytest
Alternativamente, puedes evaluar sin Pytest, lo cual es más adecuado para un entorno de notebook.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])
Usando Métricas Independientes
DeepEval es extremadamente modular, lo que facilita que cualquiera pueda usar cualquiera de nuestras métricas. Continuando con el ejemplo anterior:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# All metrics also offer an explanation
print(answer_relevancy_metric.reason)
Ten en cuenta que algunas métricas son para pipelines RAG, mientras que otras son para fine-tuning. Asegúrate de usar nuestra documentación para elegir la correcta para tu caso de uso.
Evaluando un Conjunto de Datos / Casos de Prueba en Lote
En DeepEval, un conjunto de datos es simplemente una colección de casos de prueba. Así es como puedes evaluarlos en lote:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4
Alternativamente, aunque recomendamos usar deepeval test run, puedes evaluar un conjunto de datos/casos de prueba sin usar nuestra integración con Pytest:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])
Evaluación de LLMs con Confident AI
El ciclo de vida correcto de evaluación de LLMs solo es alcanzable con la plataforma DeepEval. Te permite:
- Curar/etiquetar conjuntos de datos de evaluación en la nube
- Comparar aplicaciones LLM usando conjuntos de datos, y comparar con iteraciones anteriores para experimentar qué modelos/prompts funcionan mejor
- Ajustar métricas para resultados personalizados
- Depurar resultados de evaluación mediante trazas LLM
- Monitorear y evaluar respuestas LLM en producción para mejorar conjuntos de datos con datos del mundo real
- Repetir hasta la perfección
Todo sobre Confident AI, incluyendo cómo usar Confident, está disponible aquí.
Para comenzar, inicia sesión desde la CLI:
deepeval login
Sigue las instrucciones para iniciar sesión, crear tu cuenta y pegar tu API key en la CLI.
Ahora, ejecuta tu archivo de prueba nuevamente:
deepeval test run test_chatbot.py
Deberías ver un enlace mostrado en la CLI una vez que la prueba haya terminado de ejecutarse. ¡Pégalo en tu navegador para ver los resultados!
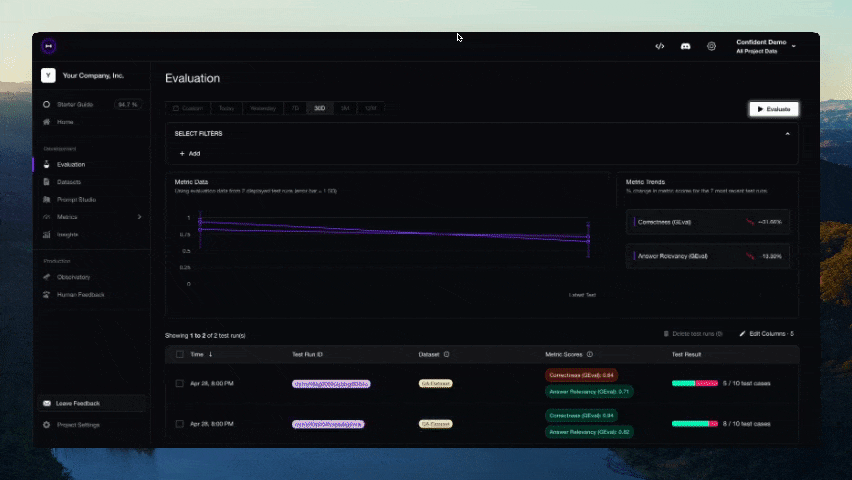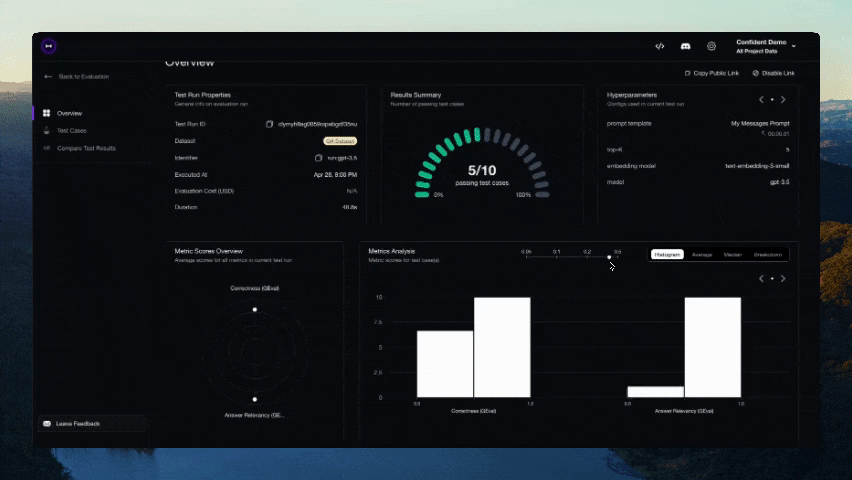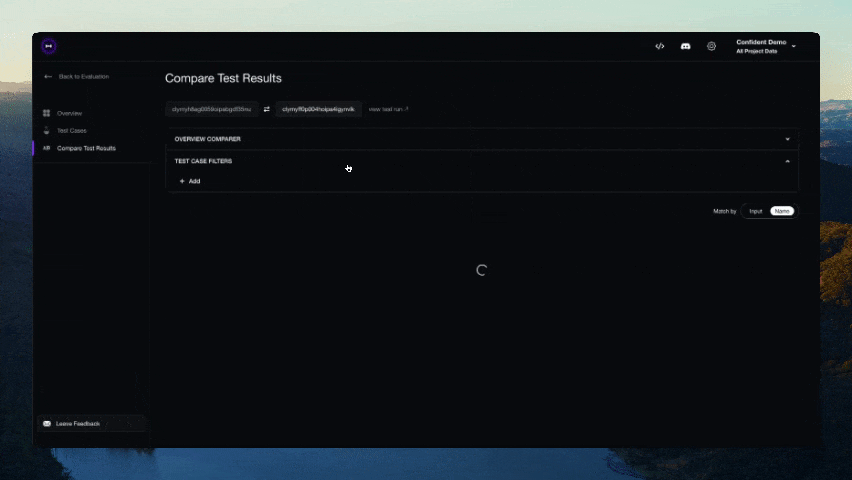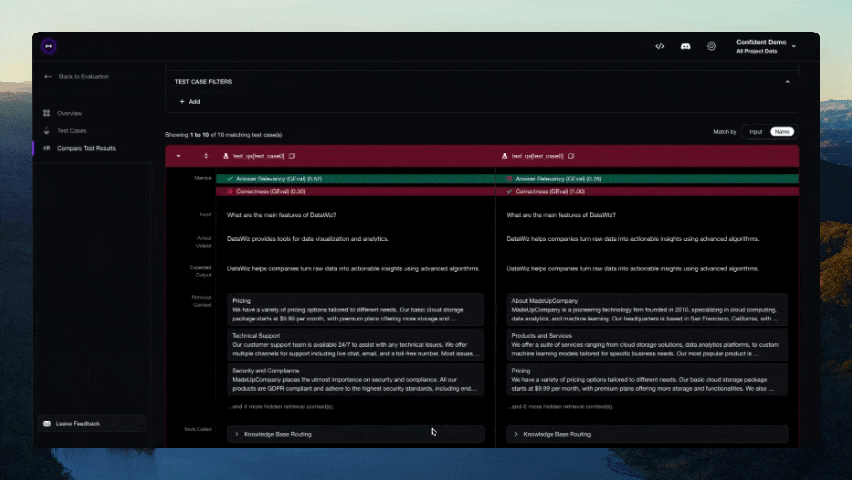
Contribuciones
Por favor lee CONTRIBUTING.md para detalles sobre nuestro código de conducta y el proceso para enviar pull requests.
Hoja de Ruta
Características:
- Integración con Confident AI
- Implementar G-Eval
- Implementar métricas RAG
- Implementar métricas conversacionales
- Creación de conjuntos de datos de evaluación
- Red-Teaming
- Métricas personalizadas DAG
- Guardarraíles
Autores
Construido por los fundadores de Confident AI. Contacta a [email protected] para cualquier consulta.
Licencia
DeepEval está licenciado bajo Apache 2.0 - ver el archivo LICENSE.md para más detalles.