🚀 Procurando uma maneira ainda mais rápida e simples para fazer scraping em escala (apenas 5 linhas de código)? Confira nossa versão aprimorada em ScrapeGraphAI.com! 🚀
🕷️ ScrapeGraphAI: Você Só Faz Scraping Uma Vez
English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português
![]()
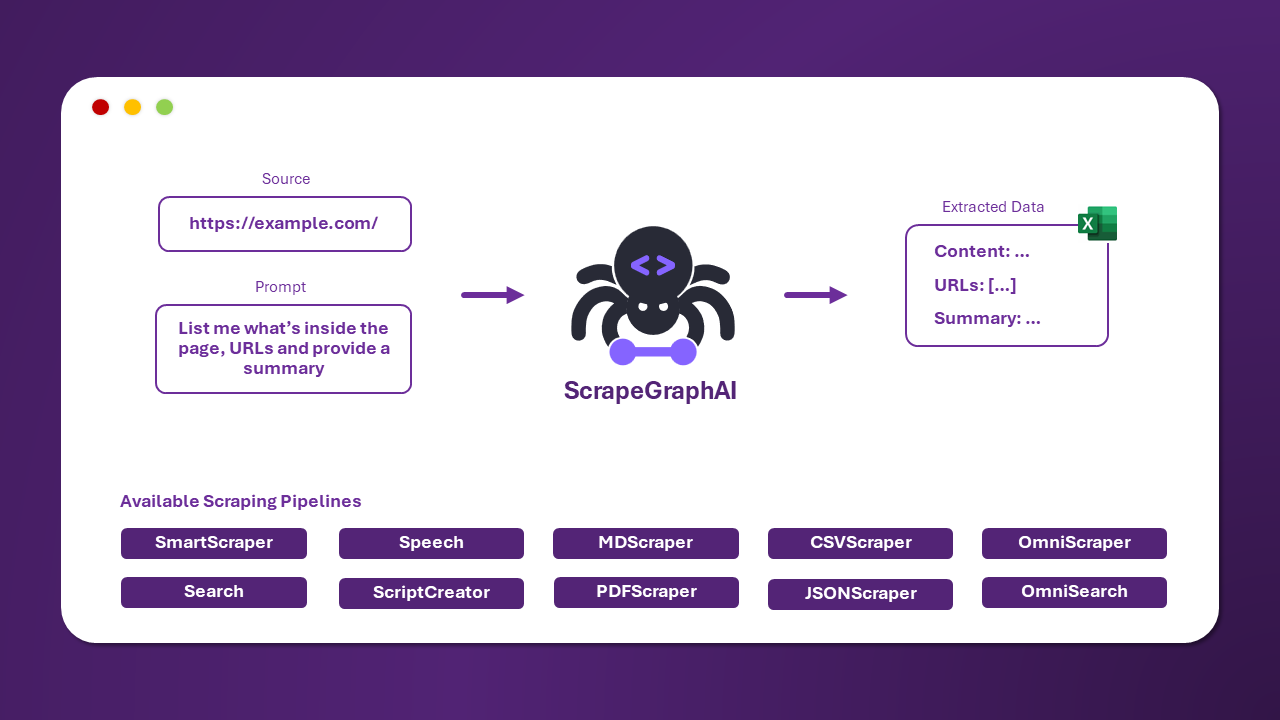
ScrapeGraphAI é uma biblioteca Python de web scraping que utiliza LLM e lógica de grafos direta para criar pipelines de scraping para sites e documentos locais (XML, HTML, JSON, Markdown, etc.).
Basta dizer quais informações você deseja extrair e a biblioteca fará isso por você!
🚀 Integrações
O ScrapeGraphAI oferece integração perfeita com frameworks e ferramentas populares para aprimorar suas capacidades de scraping. Se você está construindo com Python ou Node.js, usando frameworks LLM ou trabalhando com plataformas no-code, temos opções abrangentes de integração para você.
Você pode encontrar mais informações no seguinte link
Integrações:
- API: Documentação
- SDKs: Python, Node
- Frameworks LLM: Langchain, Llama Index, Crew.ai, CamelAI
- Frameworks Low-code: Pipedream, Bubble, Zapier, n8n, LangFlow, Dify
- Servidor MCP: Link
🚀 Instalação rápida
A página de referência para o Scrapegraph-ai está disponível na página oficial do PyPI: pypi.
pip install scrapegraphai
# IMPORTANT (for fetching websites content)
playwright install
Observação: é recomendado instalar a biblioteca em um ambiente virtual para evitar conflitos com outras bibliotecas 🐱
💻 Uso
Existem vários pipelines padrão de scraping que podem ser usados para extrair informações de um site (ou arquivo local).
O mais comum é o SmartScraperGraph, que extrai informações de uma única página com base em um prompt do usuário e uma URL de origem.
from scrapegraphai.graphs import SmartScraperGraph
# Define the configuration for the scraping pipeline
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192
},
"verbose": True,
"headless": False,
}
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com/",
config=graph_config
)
# Run the pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))
[!NOTE] Para OpenAI e outros modelos, você só precisa alterar a configuração do llm!
graph_config = { "llm": { "api_key": "SUA_CHAVE_API_OPENAI", "model": "openai/gpt-4o-mini", }, "verbose": True, "headless": False, }
A saída será um dicionário como o seguinte:
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}
Existem outros pipelines que podem ser usados para extrair informações de várias páginas, gerar scripts Python ou até mesmo gerar arquivos de áudio.
| Nome do Pipeline | Descrição |
|---|---|
| SmartScraperGraph | Scraper de página única que só precisa de um prompt do usuário e uma fonte de entrada. |
| SearchGraph | Scraper de múltiplas páginas que extrai informações dos n principais resultados de uma busca em um mecanismo de pesquisa. |
| SpeechGraph | Scraper de página única que extrai informações de um site e gera um arquivo de áudio. |
| ScriptCreatorGraph | Scraper de página única que extrai informações de um site e gera um script Python. |
| SmartScraperMultiGraph | Scraper de múltiplas páginas que extrai informações de várias páginas com base em um único prompt e uma lista de fontes. |
| ScriptCreatorMultiGraph | Scraper de múltiplas páginas que gera um script Python para extrair informações de várias páginas e fontes. |
Para cada um desses grafos, existe a versão multi. Ela permite fazer chamadas do LLM em paralelo.
É possível usar diferentes LLMs através de APIs, como OpenAI, Groq, Azure e Gemini, ou modelos locais usando Ollama.
Lembre-se de ter o Ollama instalado e baixar os modelos usando o comando ollama pull, se quiser usar modelos locais.
📖 Documentação
![]()
A documentação do ScrapeGraphAI pode ser encontrada aqui. Confira também o Docusaurus aqui.
🤝 Contribuição
Sinta-se à vontade para contribuir e junte-se ao nosso servidor no Discord para discutir melhorias e nos dar sugestões!
Por favor, consulte as diretrizes de contribuição.
🔗 API & SDKs do ScrapeGraph
Se você está procurando uma solução rápida para integrar o ScrapeGraph em seu sistema, confira nossa poderosa API aqui!

Oferecemos SDKs em Python e Node.js, facilitando a integração em seus projetos. Confira abaixo:
| SDK | Linguagem | Link do GitHub |
|---|---|---|
| Python SDK | Python | scrapegraph-py |
| Node.js SDK | Node.js | scrapegraph-js |
A documentação oficial da API pode ser encontrada aqui.
🏆 Patrocinadores


📈 Telemetria
Coletamos métricas de uso anônimas para melhorar a qualidade e a experiência do usuário do nosso pacote. Os dados nos ajudam a priorizar melhorias e garantir compatibilidade. Se desejar desativar, defina a variável de ambiente SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. Para mais informações, consulte a documentação aqui.
❤️ Contribuidores
🎓 Citações
Se você usou nossa biblioteca para fins de pesquisa, por favor, cite-nos com a seguinte referência:
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
Autores
| Informações de Contato | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
📜 Licença
O ScrapeGraphAI está licenciado sob a Licença MIT. Consulte o arquivo LICENSE para mais informações.
Agradecimentos
- Gostaríamos de agradecer a todos os contribuidores do projeto e à comunidade de código aberto pelo apoio.
- O ScrapeGraphAI deve ser usado apenas para fins de exploração de dados e pesquisa. Não nos responsabilizamos por qualquer uso indevido da biblioteca.
Feito com ❤️ por ScrapeGraph AI
{kind=link}