🚀 Auf der Suche nach einer noch schnelleren und einfacheren Methode für großangelegtes Scraping (nur 5 Codezeilen)? Schauen Sie sich unsere erweiterte Version auf ScrapeGraphAI.com an! 🚀
🕷️ ScrapeGraphAI: You Only Scrape Once
English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português
![]()
ScrapeGraphAI ist eine Web-Scraping-Python-Bibliothek, die LLM und direkte Graph-Logik verwendet, um Scraping-Pipelines für Websites und lokale Dokumente (XML, HTML, JSON, Markdown usw.) zu erstellen.
Sagen Sie einfach, welche Informationen Sie extrahieren möchten, und die Bibliothek erledigt den Rest für Sie!
🚀 Integrationen
ScrapeGraphAI bietet nahtlose Integration mit beliebten Frameworks und Tools, um Ihre Scraping-Fähigkeiten zu erweitern. Egal, ob Sie mit Python oder Node.js arbeiten, LLM-Frameworks verwenden oder auf No-Code-Plattformen tätig sind – wir decken Sie mit unseren umfassenden Integrationsoptionen ab.
Weitere Informationen finden Sie unter folgendem Link.
Integrationen:
- API: Dokumentation
- SDKs: Python, Node
- LLM-Frameworks: Langchain, Llama Index, Crew.ai, CamelAI
- Low-Code-Frameworks: Pipedream, Bubble, Zapier, n8n, LangFlow, Dify
- MCP-Server: Link
🚀 Schnelle Installation
Die Referenzseite für Scrapegraph-ai ist auf der offiziellen PyPI-Seite verfügbar: pypi.
pip install scrapegraphai
# IMPORTANT (for fetching websites content)
playwright install
Hinweis: Es wird empfohlen, die Bibliothek in einer virtuellen Umgebung zu installieren, um Konflikte mit anderen Bibliotheken zu vermeiden 🐱.
💻 Verwendung
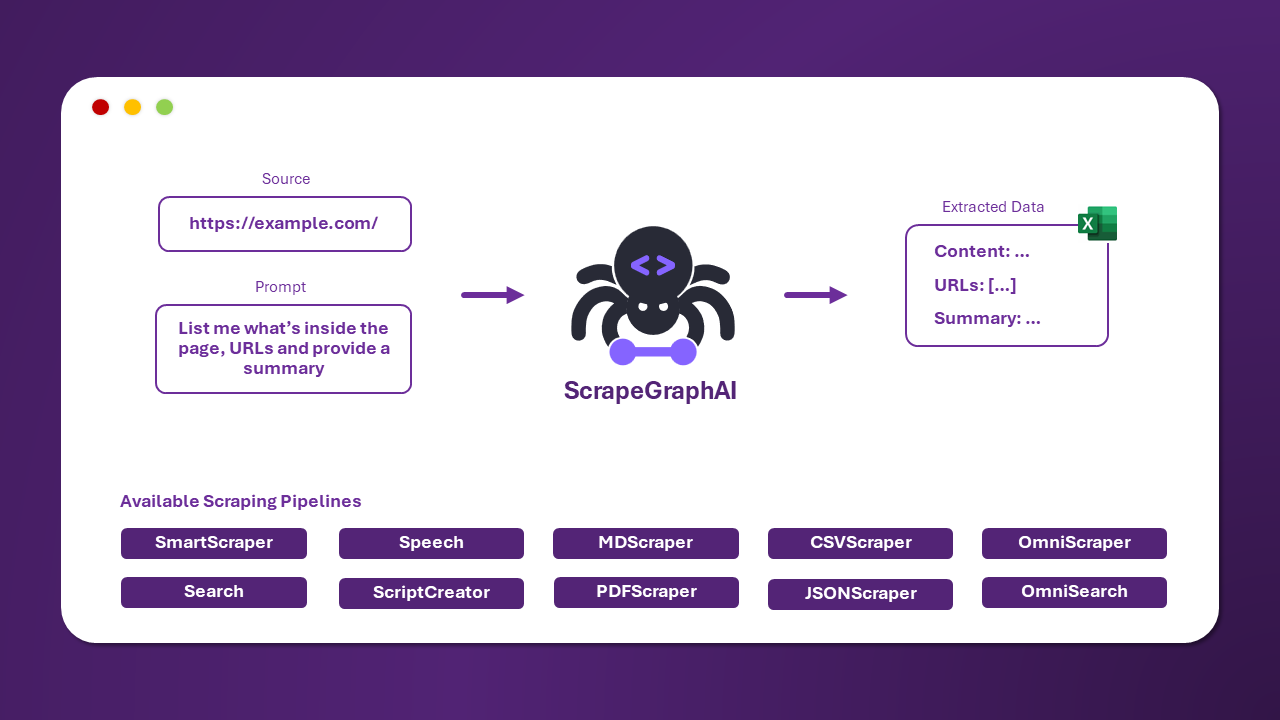
Es gibt mehrere standardmäßige Scraping-Pipelines, die verwendet werden können, um Informationen von einer Website (oder einer lokalen Datei) zu extrahieren.
Die gebräuchlichste ist der SmartScraperGraph, der Informationen von einer einzelnen Seite extrahiert, basierend auf einer Benutzeranfrage und einer Quell-URL.
from scrapegraphai.graphs import SmartScraperGraph
# Define the configuration for the scraping pipeline
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192
},
"verbose": True,
"headless": False,
}
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com/",
config=graph_config
)
# Run the pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))
[!HINWEIS] Für OpenAI und andere Modelle müssen Sie nur die LLM-Konfiguration ändern!
graph_config = { "llm": { "api_key": "IHR_OPENAI_API_SCHLÜSSEL", "model": "openai/gpt-4o-mini", }, "verbose": True, "headless": False, }
Die Ausgabe wird ein Wörterbuch wie folgt sein:
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}
Es gibt weitere Pipelines, die verwendet werden können, um Informationen von mehreren Seiten zu extrahieren, Python-Skripte zu generieren oder sogar Audiodateien zu erstellen.
| Pipeline-Name | Beschreibung |
|---|---|
| SmartScraperGraph | Einseitiger Scraper, der nur eine Benutzeranfrage und eine Eingabequelle benötigt. |
| SearchGraph | Mehrseitiger Scraper, der Informationen aus den Top-n-Suchergebnissen einer Suchmaschine extrahiert. |
| SpeechGraph | Einseitiger Scraper, der Informationen von einer Website extrahiert und eine Audiodatei generiert. |
| ScriptCreatorGraph | Einseitiger Scraper, der Informationen von einer Website extrahiert und ein Python-Skript generiert. |
| SmartScraperMultiGraph | Mehrseitiger Scraper, der Informationen von mehreren Seiten extrahiert, basierend auf einer einzelnen Anfrage und einer Liste von Quellen. |
| ScriptCreatorMultiGraph | Mehrseitiger Scraper, der ein Python-Skript zur Extraktion von Informationen von mehreren Seiten und Quellen generiert. |
Für jeden dieser Graphen gibt es die Multi-Version. Sie ermöglicht parallele Aufrufe des LLM.
Es ist möglich, verschiedene LLM über APIs zu verwenden, wie OpenAI, Groq, Azure und Gemini, oder lokale Modelle mit Ollama.
Denken Sie daran, Ollama installiert zu haben und die Modelle mit dem Befehl ollama pull herunterzuladen, wenn Sie lokale Modelle verwenden möchten.
📖 Dokumentation
![]()
Die Dokumentation für ScrapeGraphAI finden Sie hier. Schauen Sie sich auch das Docusaurus hier an.
🤝 Mitwirken
Fühlen Sie sich frei, mitzuwirken, und treten Sie unserem Discord-Server bei, um mit uns über Verbesserungen zu diskutieren und uns Vorschläge zu machen!
Bitte lesen Sie die Richtlinien für Mitwirkende.
🔗 ScrapeGraph API & SDKs
Wenn Sie nach einer schnellen Lösung suchen, um ScrapeGraph in Ihr System zu integrieren, schauen Sie sich unsere leistungsstarke API hier an!

Wir bieten SDKs in Python und Node.js an, um die Integration in Ihre Projekte zu erleichtern. Schauen Sie sich diese unten an:
| SDK | Sprache | GitHub-Link |
|---|---|---|
| Python SDK | Python | scrapegraph-py |
| Node.js SDK | Node.js | scrapegraph-js |
Die offizielle API-Dokumentation finden Sie hier.
🏆 Sponsoren


📈 Telemetrie
Wir sammeln anonyme Nutzungsdaten, um die Qualität unseres Pakets und die Benutzererfahrung zu verbessern. Die Daten helfen uns, Verbesserungen zu priorisieren und die Kompatibilität sicherzustellen. Wenn Sie sich abmelden möchten, setzen Sie die Umgebungsvariable SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. Weitere Informationen finden Sie in der Dokumentation hier.
❤️ Mitwirkende
🎓 Zitate
Wenn Sie unsere Bibliothek für Forschungszwecke verwendet haben, zitieren Sie uns bitte mit folgender Referenz:
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
Autoren
| Kontaktinformationen | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
📜 Lizenz
ScrapeGraphAI ist unter der MIT-Lizenz lizenziert. Weitere Informationen finden Sie in der LIZENZ-Datei.
Danksagungen
- Wir möchten allen Mitwirkenden des Projekts und der Open-Source-Community für ihre Unterstützung danken.
- ScrapeGraphAI ist nur für Datenexploration und Forschungszwecke gedacht. Wir sind nicht verantwortlich für jeglichen Missbrauch der Bibliothek.
Gemacht mit ❤️ von ScrapeGraph AI
{kind=link}