🚀 Vous cherchez un moyen encore plus rapide et simple de scraper à grande échelle (seulement 5 lignes de code) ? Découvrez notre version améliorée sur ScrapeGraphAI.com ! 🚀
🕷️ ScrapeGraphAI : You Only Scrape Once
English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português
![]()
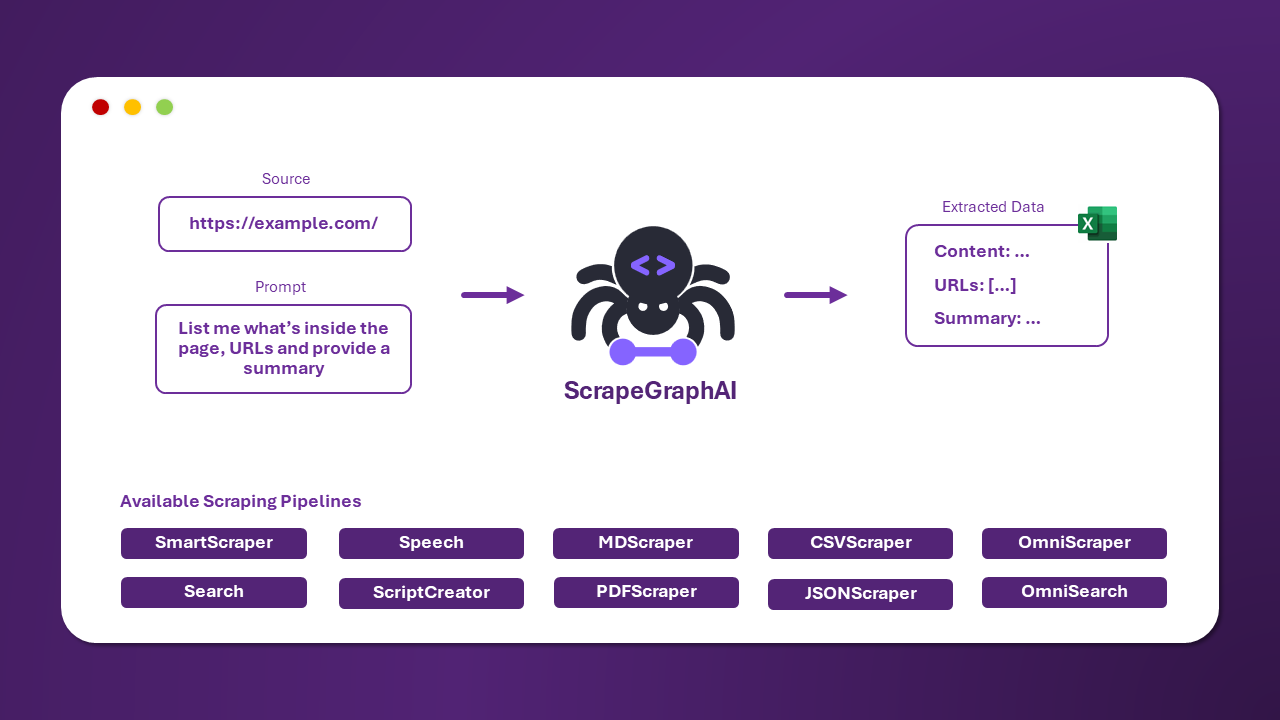
ScrapeGraphAI est une bibliothèque Python de web scraping qui utilise des LLM et une logique de graphe direct pour créer des pipelines de scraping pour des sites web et des documents locaux (XML, HTML, JSON, Markdown, etc.).
Indiquez simplement les informations que vous souhaitez extraire et la bibliothèque s'en chargera pour vous !
🚀 Intégrations
ScrapeGraphAI offre une intégration transparente avec des frameworks et outils populaires pour améliorer vos capacités de scraping. Que vous construisiez avec Python ou Node.js, utilisiez des frameworks LLM ou travailliez avec des plateformes no-code, nous vous couvrons avec nos options d'intégration complètes.
Vous pouvez trouver plus d'informations sur le lien suivant
Intégrations :
- API : Documentation
- SDKs : Python, Node
- Frameworks LLM : Langchain, Llama Index, Crew.ai, CamelAI
- Frameworks Low-code : Pipedream, Bubble, Zapier, n8n, LangFlow, Dify
- Serveur MCP : Lien
🚀 Installation rapide
La page de référence pour Scrapegraph-ai est disponible sur la page officielle de PyPI : pypi.
pip install scrapegraphai
# IMPORTANT (for fetching websites content)
playwright install
Remarque : il est recommandé d'installer la bibliothèque dans un environnement virtuel pour éviter les conflits avec d'autres bibliothèques 🐱
💻 Utilisation
Il existe plusieurs pipelines de scraping standard qui peuvent être utilisés pour extraire des informations d'un site web (ou d'un fichier local).
Le plus courant est le SmartScraperGraph, qui extrait des informations d'une seule page à partir d'une invite utilisateur et d'une URL source.
from scrapegraphai.graphs import SmartScraperGraph
# Define the configuration for the scraping pipeline
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192
},
"verbose": True,
"headless": False,
}
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com/",
config=graph_config
)
# Run the pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))
[!NOTE] Pour OpenAI et d'autres modèles, il vous suffit de modifier la configuration du LLM !
graph_config = { "llm": { "api_key": "YOUR_OPENAI_API_KEY", "model": "openai/gpt-4o-mini", }, "verbose": True, "headless": False, }
Le résultat sera un dictionnaire comme suit :
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}
Il existe d'autres pipelines qui peuvent être utilisés pour extraire des informations de plusieurs pages, générer des scripts Python ou même des fichiers audio.
| Nom du Pipeline | Description |
|---|---|
| SmartScraperGraph | Scraper mono-page qui nécessite uniquement une invite utilisateur et une source d'entrée. |
| SearchGraph | Scraper multi-pages qui extrait des informations des n premiers résultats d'un moteur de recherche. |
| SpeechGraph | Scraper mono-page qui extrait des informations d'un site web et génère un fichier audio. |
| ScriptCreatorGraph | Scraper mono-page qui extrait des informations d'un site web et génère un script Python. |
| SmartScraperMultiGraph | Scraper multi-pages qui extrait des informations de plusieurs pages à partir d'une seule invite et d'une liste de sources. |
| ScriptCreatorMultiGraph | Scraper multi-pages qui génère un script Python pour extraire des informations de plusieurs pages et sources. |
Pour chacun de ces graphes, il existe une version multi. Elle permet d'effectuer des appels au LLM en parallèle.
Il est possible d'utiliser différents LLM via des APIs, tels que OpenAI, Groq, Azure et Gemini, ou des modèles locaux en utilisant Ollama.
N'oubliez pas d'avoir Ollama installé et de télécharger les modèles en utilisant la commande ollama pull, si vous souhaitez utiliser des modèles locaux.
📖 Documentation
![]()
La documentation de ScrapeGraphAI peut être trouvée ici. Consultez également le Docusaurus ici.
🤝 Contributions
N'hésitez pas à contribuer et à rejoindre notre serveur Discord pour discuter avec nous des améliorations et nous faire des suggestions !
Veuillez consulter les lignes directrices pour contribuer.
🔗 API & SDKs ScrapeGraph
Si vous recherchez une solution rapide pour intégrer ScrapeGraph dans votre système, consultez notre puissante API ici !

Nous proposons des SDKs en Python et Node.js, facilitant l'intégration dans vos projets. Consultez-les ci-dessous :
| SDK | Langage | Lien GitHub |
|---|---|---|
| SDK Python | Python | scrapegraph-py |
| SDK Node.js | Node.js | scrapegraph-js |
La documentation officielle de l'API peut être trouvée ici.
🏆 Sponsors


📈 Télémétrie
Nous collectons des métriques d'utilisation anonymes pour améliorer la qualité de notre package et l'expérience utilisateur. Les données nous aident à prioriser les améliorations et à assurer la compatibilité. Si vous souhaitez désactiver cette fonctionnalité, définissez la variable d'environnement SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. Pour plus d'informations, veuillez consulter la documentation ici.
❤️ Contributeurs
🎓 Citations
Si vous avez utilisé notre bibliothèque à des fins de recherche, veuillez nous citer avec la référence suivante :
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
Auteurs
| Coordonnées | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
📜 Licence
ScrapeGraphAI est sous licence MIT. Voir le fichier LICENCE pour plus d'informations.
Remerciements
- Nous tenons à remercier tous les contributeurs au projet et la communauté open-source pour leur soutien.
- ScrapeGraphAI est destiné à être utilisé uniquement pour l'exploration de données et la recherche. Nous ne sommes pas responsables de toute utilisation abusive de la bibliothèque.
Fait avec ❤️ par ScrapeGraph AI
{kind=link}